
프롤로그: 개인정보 보호는 선택이 아닌 필수다
Tech
바야흐로 '데이터의 시대'입니다. 최근 기업들은 방대한 비정형 텍스트 데이터를 수집하여 서비스 개선, 사용자 행동 분석, 자동화 등 다양한 가치를 창출하고 있습니다.
하지만 이러한 데이터의 홍수 속에는 이름, 주민등록번호, 계좌번호, 상세 주소 등 민감한 개인정보(PII, Personally Identifiable Information)가 파편화되어 섞여 있다는 치명적인 리스크가 도사리고 있습니다.
문제는 이러한 정보들이 별도의 보호 장치 없이 시스템에 노출되거나 처리될 때 발생합니다. 실제로 2025년 한 해에만 SK텔레콤(2,324만 명), 롯데카드(297만 명), 쿠팡(3,370만 명) 등 국내 유수 기업들에서 대규모 개인정보 유출 사고가 잇따라 발생했습니다. 대학과 병원 등 공공기관의 보안 사고까지 더해지며, 개인정보 보호에 대한 사회적 요구와 법적 규제는 그 어느 때보다 강력해지고 있습니다.
이제는 사고 발생 후의 대처보다, AI가 데이터를 처리하는 전 과정에서 개인정보를 원천적으로 탐지하고 마스킹하는 조치는 필수입니다. 데이터 기반의 모든 서비스에서 개인정보 보호는 비즈니스의 기본이며, 특히 금융권처럼 민감한 정보를 다루는 분야에서는 AI 모델로 유입되는 데이터를 사전에 식별하고 마스킹하는 체계가 반드시 뒷받침되어야 합니다.
기존의 단순 키워드 매칭이나 정규식 방법은 문맥을 고려하지 못해 정형화된 패턴만 탐지하는 한계가 명확했습니다. 반면, 최근 비약적으로 발전한 자연어처리 기술은 문장의 의미를 이해하여 "보호해야 할 정보인지"를 스스로 판단하는 수준에 이르렀습니다. 본 포스팅에서는 제논이 이러한 기술적 배경을 바탕으로, BERT-CRF 기반의 개체명 인식 모델을 활용해 개인정보 마스킹 모델을 구축한 과정을 공유하고자 합니다.
단순한 모델 적용기를 넘어, 실무 환경에서 마주한 고민들을 중점적으로 다룹니다.
Zero-base Data Generation: 외부 데이터 반입이 불가능한 내부망(On-premise) 환경에서 어떻게 학습 데이터를 생성했는가?
Mitigating Class Imbalance: 전체 토큰의 90%가 'O(Outside)'인 상황에서 희소한 개인정보 클래스 불균형을 어떻게 해결했는가?
Performance & Efficiency: 정규표현식 대비 얼마나 정확하며, LLM 대비 얼마나 효율적인가?
안전한 데이터 활용을 위한 기술적 여정을 지금부터 시작합니다.
이 장에서는 개인정보 마스킹 모델을 구현하기 위한 핵심 기술인 개체명 인식과 BIO 태깅의 개념을 짚어보고, 문맥을 이해하는 BERT(Bidirectional Encoder Representations from Transformers)와 문법적 오류를 교정하는 CRF(Conditional Random Field)가 어떻게 결합되어 작동하는지 전체적인 아키텍처를 소개합니다.
개체명 인식(Named Entity Recognition, NER)은 문장 내에서 특정한 의미를 갖는 단어를 찾아내고, 이를 사전에 정의된 범주(인물, 장소, 날짜 등)로 분류하는 자연어 처리 기술입니다. 금융, 의료, 법률 등 특수 도메인에서는 일반적인 범주 외에도 '계좌번호', '가맹점명' 등 도메인 특화 개체명을 정의하여 민감 정보를 식별하는 데 활용합니다.
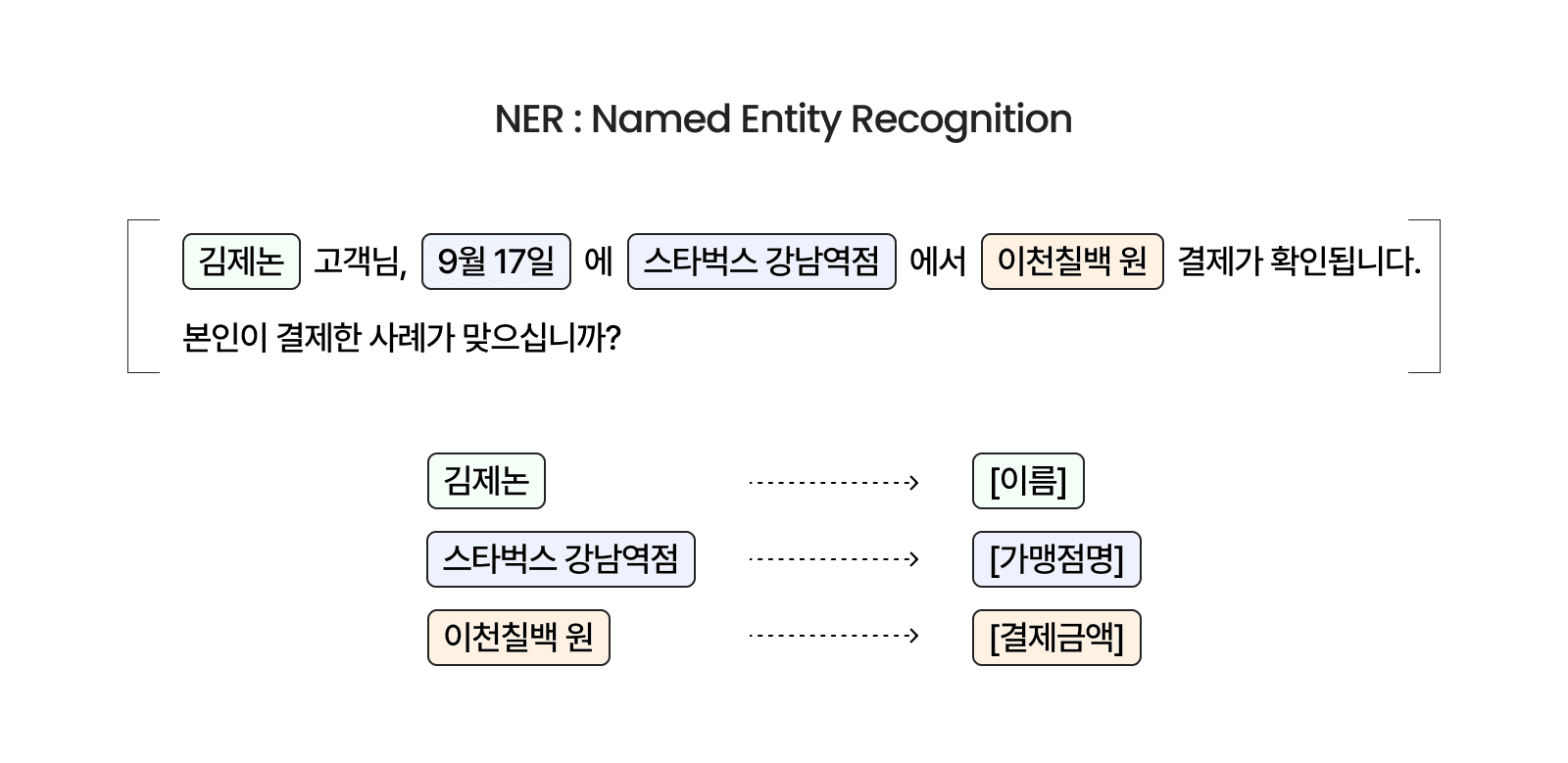
이미지 1. 개체명 인식(NER)을 활용한 문장 내 주요 정보 추출 예시. 출처: 제논
예를 들어, 다음과 같은 고객의 문의 내역이 있다고 가정해 보겠습니다.
“김제논 고객님, 9월 17일에 스타벅스 강남역점에서 이천칠백 원 결제가 확인됩니다. 본인이 결제한 사례가 맞으십니까?”
NER 모델은 이 문장을 분석하여 아래와 같이 의미 있는 정보를 추출합니다.
"김제논" →
[이름],"스타벅스 강남역점" →
[가맹점명],"이천칠백 원" →
[결제금액]
BIO 태그 체계: 정답을 알려주는 약속
모델이 "스타벅스 강남역점"이 하나의 단어가 아니라 여러 토큰(Token)으로 이루어진 긴 개체명임을 알게 하려면 어떻게 해야 할까요? 이때 사용하는 것이 BIO 태깅(BIO Tagging)입니다. BIO는 세 가지 태그로 구성됩니다:
B (Begin): 개체명의 시작 토큰
I (Inside): 개체명의 내부에 포함된 토큰
O (Outside): 개체명이 아닌 일반 토큰

이미지 2. BIO 태그 체계. 출처: 제논
이처럼 BIO 태그를 사용하면 모델은 "여기서부터 여기까지가 하나의 가맹점명이다"라는 경계 정보를 명확하게 학습할 수 있습니다.
저희는 한국어 문맥 이해에 특화된 KcBERT(Korean comments BERT)를 기반으로, 시퀀스(순서)의 일관성을 잡아주는 CRF 레이어를 결합한 아키텍처를 채택했습니다.
Why BERT? (문맥을 읽는 눈)
BERT는 대규모 텍스트로 사전 학습(Pre-training)된 언어 모델입니다. 양방향(Bidirectional)으로 문맥을 파악하기 때문에, 같은 단어라도 주변 단어에 따라 의미가 달라지는 것을 구분할 수 있습니다.
예: "배" → 먹는 배인지, 타는 배인지 구분
뉴스 댓글 등으로 학습되어 구어체와 신조어에 강한 KcBERT를 사용
Why CRF? (문법을 지키는 교정자)
BERT만 사용해도 각 토큰을 분류할 수 있지만, 한 가지 약점이 있습니다. 각 토큰을 독립적으로 예측하다 보니, 문맥상 말이 안 되는 태깅 실수를 할 때가 있습니다.
BERT의 실수 예시:
이름_B다음에 뜬금없이주소_I가 온다고 예측. (이름이 시작됐는데 갑자기 주소의 중간이 나올 수는 없음)
이 문제를 해결하기 위해 CRF를 마지막 층에 추가했습니다. CRF는 토큰 하나하나만 보는 것이 아니라, 앞뒤 토큰 간의 관계(Transition Probability)를 학습합니다.
학습 내용: "
이름_B뒤에는이름_I가 올 확률이 높고,주소_I가 올 확률은 0에 가깝다."효과: 문장 전체를 보았을 때 가장 자연스럽고 일관성 있는 태그 시퀀스를 찾아줍니다.
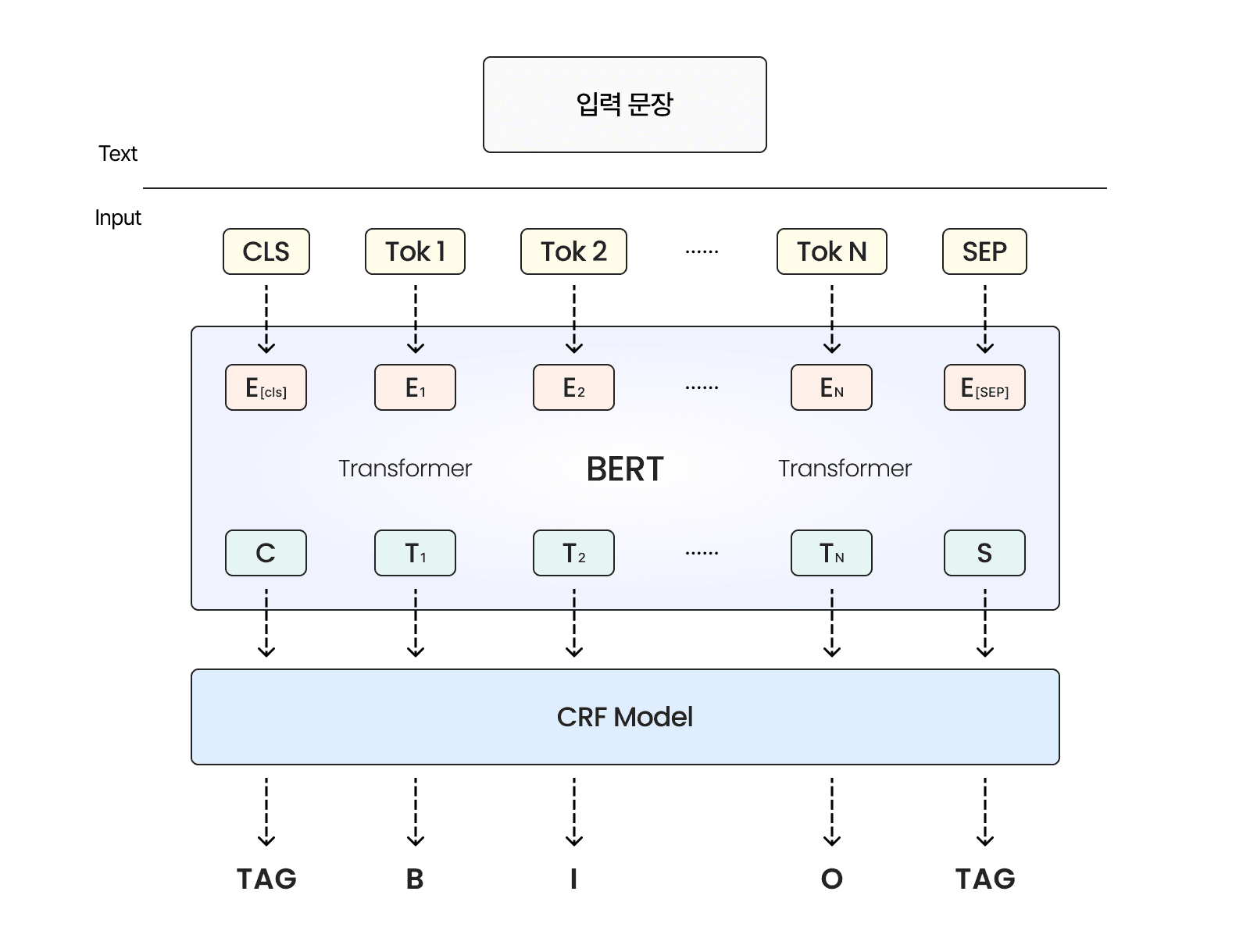
이미지 3. BERT-CRF 기반 개체명 인식 모델의 전체 아키텍처 및 태깅 프로세스(제논 재구성).
출처: Cheng, J., et al. [1]
최종적인 모델의 데이터 처리 흐름은 다음과 같습니다.
1. 입력 문장을 BERT 토크나이저로 분절한 후, 각 토큰을 임베딩 벡터로 변환합니다.
2. BERT는 양방향 문맥 정보를 반영한 토큰 임베딩을 출력합니다.
3. 이 임베딩이 CRF 레이어로 전달되며, 시퀀스 전체의 레이블 조합 중 가장 높은 확률을 갖는 시퀀스를 예측합니다.
이렇게 모델 구조를 설계했지만, 곧바로 난관에 봉착했습니다. 바로 "보안 규정상 실제 고객 데이터를 학습에 사용할 수 없다"는 점이었습니다. 모델은 준비되었지만, 정작 가르칠 교과서가 없는 상황. 저희는 이 문제를 해결하기 위해 제로베이스에서 데이터를 생성하는 전략을 수립해야 했습니다.
개발 과정에서 가장 큰 제약 중 하나는 실제 금융권 데이터를 활용할 수 없었다는 점입니다. 실제 고객사의 서비스 적용을 목표로 했지만, 보안 정책상 내부 데이터 접근이 엄격히 제한되어 있었습니다. 결국, 완전히 외부에서 제로베이스로 학습 데이터를 구축해야 했습니다. 개발 과정에서 마주한 여러 고민 중, 이번 글에서는 제로베이스 환경에서 데이터를 어떻게 구성했는지, 그리고 클래스 불균형 문제에 어떤 방식으로 접근했는지를 중심으로 살펴보겠습니다.
1) 첫 번째 시도: LLM을 활용한 데이터 생성과 한계
내부의 데이터를 사용할 수 없는데 외부에서 어떻게 데이터를 구축해야할까? 내부 데이터를 볼 수 없다면, 외부에서 가장 유사한 데이터를 만들어내야 했습니다.
가장 먼저 떠오른 접근법은 최근 비약적인 성능 향상을 이룬 거대 언어 모델(Large Language Model, LLM)을 활용하는 것이었습니다. LLM은 방대한 지식을 학습했기 때문에, 적절한 프롬프트 엔지니어링(Prompt Engineering)을 거치면 금융권 상담 상황을 꽤 그럴싸하게 흉내 낼 수 있을 것이라 판단했습니다. 저희는 GPT-5와 같은 모델에게 페르소나를 부여하고 다음과 같이 요청했습니다.
“너는 카드사 고객센터에 문의하는 고객이야. 이중 결제가 발생해서 환불을 요청하는 상황을 자연스러운 구어체 문장으로 100개 생성해줘.”
초기 결과는 훌륭해 보였습니다. LLM은 "제가 어제 강남역에서 결제했는데 두 번 긁힌 것 같아요", "카드 분실 신고를 하려고 합니다"와 같이 문법적으로 완벽하고 자연스러운 문장들을 생성했습니다. 카드사나 증권사에서 사용하는 전문 용어(전표 매입, 할부 철회 등)도 적재적소에 사용되어 초기에는 이 데이터만으로도 충분할 것이라 생각했습니다.
하지만, 이렇게 생성된 수천 개의 문장을 분석하고 BERT 모델 학습을 시도해 본 결과, 본질적인 한계점이 드러났습니다. 바로 학습 데이터셋의 다양성이 부족하다는 점이었습니다.
패턴의 단조로움: LLM은 확률적으로 가장 '그럴듯한' 단어를 선택하여 문장을 생성합니다. 그러다 보니 생성된 문장들이 마치 모범 답안처럼 정제되어 있고, 문장의 구조(주어-목적어-서술어)가 지나치게 일관된 경향을 보였습니다.
현실성을 담지 못한 데이터: 실제 고객 상담 현장에서는 '선결제/즉시출금', '도난 분실 해제', '한도 상향 심사' 등 복잡한 도메인 시나리오가 존재합니다. 또한 화가 난 고객, 말을 더듬는 고객, 비문을 사용하는 경우, 혹은 "아니 그게 아니고, 저번에 말한 거 있잖아"와 같이 문맥이 생략된 대화도 빈번합니다. 하지만 LLM은 일반적이고 평이한 케이스에 편중되어 데이터를 생성했습니다.
BERT와 같은 인코더 기반 모델은 단순히 단어를 외우는 것이 아니라, 문장 내의 복잡한 문맥(Context)을 이해하고 그 속에서 엔티티(Entity)의 역할을 추론하는 능력이 핵심입니다. 학습 데이터의 패턴이 단조로우면 모델은 쉬운 패턴에만 과적합 되어, 조금만 낯선 표현이나 복잡한 문장이 들어와도 성능이 급격히 떨어지는 결과를 초래합니다. 결론적으로, LLM 단독 생성 방식은 '양'은 채울 수 있었지만, 실무 환경을 커버할 수 있는 '질(다양성)'을 확보하기에는 역부족이었습니다.
2) 돌파구: AI Hub 민원 데이터셋을 활용한 '시나리오 이식’
LLM이 스스로 다양한 상황을 상상하는 데 한계가 있다면, "이미 다양한 상황이 담겨 있는 실제 데이터"를 가이드로 주면 어떨까? 이 질문에서 출발하여 AI Hub의 '민간 민원 상담 LLM 사전학습 및 Instruction Tuning 데이터[2]'를 시드 데이터(Seed Data)로 활용하기로 결정했습니다.
이 데이터셋을 선택한 이유는 명확했습니다. 저희가 직접 "이중 결제 상황을 만들어줘"라고 주제를 한정하지 않아도, 해당 데이터셋 안에는 이미 카드사에서 발생할 수 있는 40건 이상의 실제 민원 시나리오가 포함되어 있었기 때문입니다. 최근에 구축하여 이용내역 안내, 선결제/즉시출금, 도난/분실 신청/해제, 한도상향 접수/처리, 결제대금 안내 등 상상만으로는 떠올리기 힘든 디테일한 업무 유형들이 데이터셋에 녹아 있었습니다.
저희는 데이터 구축 파이프라인을 다음과 같이 고도화했습니다.
시드 데이터 샘플링: AI Hub 데이터셋에서 무작위로 데이터 샘플을 추출합니다.
LLM Rewrite: 추출한 샘플을 LLM에게 프롬프트로 제공하며, 이를 원하는 용도에 맞게 변형하거나 문체를 다양하게 바꾸도록 지시합니다.
다양성 확보: 원본 데이터의 다양한 업무 유형을 통해 데이터의 다양성을 확보하여 현실적인 시나리오를 녹여낼 수 있었습니다.
이 방식은 BERT 모델 학습에 결정적인 영향을 미쳤습니다. 모델은 이제 단순한 패턴이 아니라, "고객이 불만을 표출하는 문맥", "정보를 확인하려는 의문의 문맥" 등 문장의 의도와 흐름을 학습하기 시작했습니다.
3) 남겨진 과제: 비식별화된 공백과 클래스 불균형
시드 데이터를 통해 시나리오의 다양성 문제는 해결했지만, 여전히 넘어야 할 산이 남아 있었습니다.
첫째, 비식별화 문제입니다. AI Hub 데이터는 개인정보 보호를 위해 이름, 주소, 전화번호 등이 모두 ▲와 같이 마스킹 처리된 상태였습니다. 모델을 학습시키기 위해서는 이 자리에 실제와 유사한 가짜 개인정보를 채워 넣고, 정확한 정답 라벨을 달아주는 '재식별화(Re-identification)' 과정이 필요했습니다.
둘째, 클래스 불균형(Class Imbalance) 문제입니다. 시드 데이터를 분석해 보니, '이름’, '메일주소' 같은 일반적인 개체명은 거의 모든 문장에 등장하는 반면, '가맹점명', '결제금액'과 같은 핵심 개인 정보는 등장하지 않았습니다. NER 모델은 데이터가 많은 클래스는 잘 맞추지만, 데이터가 적은 희귀 클래스는 무시하거나 ‘O’ 태그로 예측해버리는 경향이 있습니다. 저희가 목표로 하는 것은 모든 개인정보를 빠짐없이 탐지하는 강건한(Robust) 모델이었기에, 특정 클래스에 편향되지 않고 모든 클래스를 골고루 학습할 수 있는 전략이 절실했습니다.
단순히 빈 칸을 채우는 것을 넘어, 어떻게 하면 희귀한 클래스(Rare Class)의 데이터를 증강하고 모델의 학습 균형을 맞출 수 있었는지, 데이터 밸런싱(Data Balancing) 전략에 대해서는 다음 챕터에서 구체적으로 다루겠습니다.
앞서 데이터를 생성했지만, 단순히 데이터의 양만 늘린다고 능사는 아니었습니다. NER 태스크의 성능을 떨어뜨리는 고질적인 문제, 바로 Class Imbalance가 기다리고 있었기 때문입니다. 저희는 이 문제를 크게 두 가지 관점에서 분석하고 해결책을 설계했습니다.
1) 문제의 본질: 왜 모델은 소수 클래스를 외면하는가?
첫째, 타겟 클래스 간의 극심한 불균형(Inter-Class Imbalance)입니다. 이상적인 학습 환경은 이름, 가맹점명, 상세주소 등 모든 타겟 클래스가 균등하게 분포하는 것입니다. 하지만 현실 데이터는 '이름'이나 '메일주소'는 빈번하게 등장하는 반면, '가맹점명'이나 '결제금액'과 같은 민감 정보는 매우 희소하게 등장합니다. 딥러닝 모델은 기본적으로 전체 손실(Global Loss)을 최소화하는 방향으로 최적화됩니다. 만약 학습 데이터에 '이름'이 1,000개, '상세주소'가 10개뿐이라면, 모델은 상세주소 10개를 모두 틀리더라도 다수인 이름 1,000개를 맞추는 쪽으로 가중치를 업데이트합니다. 결과적으로 모델은 데이터가 풍부한 클래스에 과적합(Overfitting)되고, 정작 보안상 더 중요할 수 있는 희소 개인정보는 노이즈로 취급하여 학습하지 못하는 편향이 발생합니다.
둘째, 배경 클래스('O' 태그)의 압도적 비중입니다. NER 태스크의 특성상, 문장에서 실제 개체명으로 분류되는 토큰은 극소수이며, 나머지 90% 이상은 의미 없는 일반 토큰인 'O' 태그로 라벨링됩니다. 이 경우 모델은 "모든 토큰을 'O'라고 예측"하기만 해도 90% 이상의 정확도(Accuracy)를 보이는 문제점을 갖습니다. 모델 입장에서는 복잡한 문맥을 파악해 개체명을 찾다가 틀려 벌점(Loss)을 받느니, 무조건 'O'라고 답하는 것이 가장 안전한 선택이 되기 때문입니다. 이는 결국 개체명 탐지 자체를 소극적으로 만들게 됩니다.
이 두 가지 문제는 서로 맞물리면서, 모델이 소수 클래스는 무시하고, 대부분의 토큰을 ‘O’로 분류하는 방향으로 학습될 위험을 내포합니다. 이를 해결하기 위해서는 학습 데이터 구성과 손실 함수 설계 등 다양한 측면에서 Class Imbalance를 고려한 전략이 필요합니다.
2) 해결 전략 A: LLM 기반의 데이터 밸런싱
저희는 가장 먼저 데이터 생성 단계에서부터 물리적인 불균형을 해소하고자 했습니다. 기존의 랜덤 샘플링 방식 대신, LLM을 활용한 증강(Augmentation)을 도입했습니다. 시드 데이터에 특정 클래스(예: 이름, 메일주소)만 편중되어 있다면, 프롬프트 엔지니어링을 통해 희귀 클래스(가맹점명, 결제금액 등)가 포함된 문맥을 강제로 생성해냈습니다. 희귀 클래스가 자연스러운 문맥 속에서 10개 이상의 다양한 변형을 갖도록 유도했습니다. 이를 통해 모델은 희귀한 클래스에 대해서도 충분한 문맥적 단서를 학습할 수 있는 기반을 마련했습니다.
3) 해결 전략 B: Effective Number 기반의 손실 함수 재설계
데이터 증강으로도 해결되지 않는 미세한 불균형은 손실 함수(Loss Function) 레벨에서 제어했습니다. 이때 단순한 빈도 역수(Inverse Frequency)가 아닌, 유효 샘플 수(Effective Number of Samples) 개념을 도입하여 클래스 가중치(Class Weight)를 정교하게 설계했습니다.
정보 이론적 관점에서 볼 때, 데이터가 많아질수록 새로운 샘플이 제공하는 정보량의 한계 효용은 체감합니다. 즉, 동일한 클래스의 1번째 데이터는 모델에게 새로운 정보를 주지만, 1,000번째 데이터는 앞선 999개와 유사한 특성을 공유하므로 정보의 중복성이 높습니다. 이 점에 착안하여, 샘플의 단순 개수가 아닌 '정보의 유효 크기'를 기준으로 가중치를 산출했습니다.
희귀 클래스: 높은 중복성을 가지지 않으므로 상대적으로 높은 가중치를 부여하여, 모델이 한 번 틀릴 때마다 큰 페널티를 받도록 유도했습니다.
빈출 클래스('O' 포함): 이미 충분한 정보량을 가지고 있으므로 가중치를 낮춰, 학습 과정에서 발생하는 그래디언트(Gradient)가 'O' 태그에 의해 지배되는 현상을 억제했습니다.
이러한 가중치 재조정은 모델이 "O라고 찍는 안전한 선택"을 할 때 얻는 이득을 줄이고, "희귀 클래스를 맞췄을 때 얻는 보상"을 극대화하여 학습의 균형점을 올바른 방향으로 이동시켰습니다.
4) 해결 전략 C: Context Window 샘플링
마지막으로, 학습 효율성을 극대화하기 위해 입력 데이터의 구성 방식을 변경했습니다. 문장 전체를 통째로 넣는 기존 방식은 불필요한 'O' 태그가 과도하게 포함되어 학습 편향을 유발합니다. 이를 방지하기 위해 개체명 중심의 윈도우 샘플링을 적용했습니다. 개체명이 등장하는 위치를 기준으로 앞뒤 일정 범위(Context Window)의 문맥만을 잘라내어 학습 데이터로 구성했습니다. 이 방식은 모델이 개인정보가 등장하기 직전/직후의 결정적인 문맥 패턴에 집중하게 만들며, 전체 데이터셋에서 'O' 태그가 차지하는 절대적인 비중을 낮추는 효과를 가져왔습니다. 단, 문맥이 너무 짧아지면 의미 파악이 불가능해지는 부작용을 막기 위해, 최소 토큰 길이(Minimum Token Length)를 설정하여 문맥의 의미적 완결성을 보장했습니다.
지금까지 보안이 생명인 금융 도메인의 특수성 속에서 '제로베이스 데이터 구축'과 '클래스 불균형 해결'이라는 두 가지 난제를 어떻게 기술적으로 돌파했는지 상세히 공유해 드렸습니다. 물론 이 외에도 비식별화된 데이터를 현실적인 값으로 치환하는 Re-identification 전략이나, 조사와 결합된 엔티티 경계(Entity Boundary) 문제 등 실무적인 디테일이 더 존재합니다만, 본 글에서는 모델의 성능을 결정짓는 가장 핵심적인 뼈대들을 중심으로 다루었습니다.
이제 우리의 시선을 내부에서 외부로 돌려볼 차례입니다. 과연 다른 연구자들은 이 까다로운 개인정보 마스킹 문제를 어떻게 풀고 있을까요? 다음 장에서는 최신 연구 동향을 통해 본 프로젝트의 기술적 위치를 점검해 보겠습니다.
지금까지 제로베이스에서 데이터를 구축하고 클래스 불균형을 해결하며 자체 모델을 개발한 과정을 공유했습니다. 그렇다면 현재 학계와 글로벌 산업계에서는 개인정보 마스킹 문제를 어떻게 풀고 있을까요?
2024년과 2025년에 발표된 최신 연구들을 살펴보면, 흐름은 크게
1) LLM의 한계와 합성 데이터,
2) 실용성을 위한 경량화(Efficiency),
3) 도메인 및 언어 특화 라는 세 가지 핵심 줄기로 요약됩니다.
흥미로운 점은, 이러한 최신 연구 결과들이 본 프로젝트가 선택한 기술적 의사결정들과 부합하다는 사실입니다.
1) LLM, 만능열쇠일까? : 합성 데이터와 정보 손실의 딜레마
최근 연구들은 LLM을 비식별화의 도구로 쓰되, 그 한계를 냉정하게 평가하고 있습니다.
Not What the Doctor Ordered: Surveying LLM-based De-identification and Quantifying Clinical Information Loss[3] (EMNLP, 2025): 이 연구는 LLM을 이용한 비식별화가 개인정보를 잘 탐지하는 듯하지만, 실제로는 환자에게 중요한 정보(진단명, 약물 등)까지 과도하게 제거하거나 변형하는 치명적인 단점이 있음을 지적했습니다. 금융 데이터 역시 숫자 하나, 단어 하나의 무결성이 매우 중요하기 때문에, 생성형 모델 특유의 환각(Hallucination) 위험성은 실제 서비스 적용에 큰 걸림돌이 될 수 있습니다. 이는 우리가 통제 가능한 BERT-CRF 모델을 구축해야 하는 하나의 근거이기도 합니다.
SPY: Enhancing Privacy with Synthetic PII Detection Dataset[4] (NAACL, 2025): 이 연구는 LLM을 직접 마스킹에 쓰는 대신, 고품질의 합성 데이터셋(Synthetic Dataset)을 만드는 도구로 활용할 것을 제안했습니다. 특히 단순 생성이 아니라 '직업(Occupation)'이나 '성격(Personality)' 같은 페르소나를 부여해 데이터의 다양성을 확보했습니다. 이는 저희가 시드 데이터를 기반으로 다양한 금융 민원 시나리오를 확장하여 데이터 편향을 극복했던 접근 방식과 일맥상통하는 결과입니다.
2) 무거운 모델을 가볍게 : 지식 증류와 하이브리드 접근
현업에서는 성능만큼이나 '비용'과 '속도'가 중요합니다. 이에 따라 거대 모델의 지식을 작은 모델로 옮기거나, 규칙 기반 방식을 결합하는 실용적 연구들이 주목받고 있습니다.
Resource-Efficient Anonymization of Textual Data via Knowledge Distillation from Large Language Models[5] (COLING, 2025): 해당 연구에서는 LLM의 지식을 소형 모델로 옮기는 지식 증류(Distillation)와 함께, 정규표현식을 결합한 하이브리드 파이프라인을 제안했습니다. 최신 연구에서도 여전히 정규식과 모델을 상호보완적으로 사용하는 하이브리드 접근법이 표준임을 확인할 수 있었습니다.
GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer[6] (NAACL, 2024): 이 연구는 사전 정의된 엔티티만 탐지하는 기존 한계를 넘어, 훈련하지 않은 새로운 유형도 유연하게 찾는 제로샷(Zero-shot) 모델을 제안했습니다. 비록 금융 도메인의 특성을 고려하여 저희는 BERT-CRF를 선택했지만, 무거운 LLM 대신 효율적인 소형 모델(BiLM)을 사용하는 접근법은 본 프로젝트와 유사합니다. 특히 Negative Entity Sampling을 통해 모델의 과적합을 막고 학습 균형을 맞추는 기법은 저희가 클래스 불균형 문제를 해결하기 위해 도입한 전략의 타당성을 뒷받침해줍니다.
3) 한국어와 도메인 특화 : 범용 모델이 놓치는 디테일
범용 모델(General LLM)보다는 특정 언어에 특화된 모델이 여전히 강력한 성능을 발휘한다는 연구 결과도 있습니다.
Thunder-DeID: Accurate and Efficient De-identification Framework
for Korean Court Judgments[7] (EMNLP, 2025): 이 연구는 고민했던 '데이터 부재 해결 전략'과 '한국어 특화 처리' 방식을 그대로 보여줍니다. 원본 데이터 접근이 불가능한 법률 도메인에서, 비식별화된 문서를 시드 데이터로 활용하는 방식을 사용했습니다. 특히 주목할 점은 형태소 분석기(Mecab)의 활용입니다. 저희는 프로젝트 일정상 조사를 분리하는 전처리를 깊게 적용하지 못했는데, 이 논문에서는 Mecab을 이용해 명사와 조사를 정밀하게 구분함으로써 성능을 높였습니다. 이는 "한국어와 같은 교착어에서는 형태소 분석이 필수적"이라는 저희 가설과 맞아 떨어지며, 향후 고도화 과정에서 반드시 적용해야 할 개선점임을 시사합니다. 결국 도메인은 달라도(금융 vs 법률), 민감 정보를 다루는 내부망 환경에서의 생존 전략은 통한다는 것을 알 수 있었습니다.
💡 요약 및 시사점
최신 연구 동향을 종합해볼 때, "무조건 최신 LLM을 쓰는 것이 정답은 아니다"라는 결론에 도달합니다.
Safety: LLM은 직접 마스킹 도구로 쓰기엔 환각과 정보 손실 리스크가 존재합니다.
Efficiency: 실제 서비스 환경(On-premise)에서는 경량화된 특화 모델(BERT)과 정규 표현식을 결합하는 하이브리드 접근법이 속도와 정확도 면에서 합리적인 선택지가 될 수 있습니다.
Specialty: 특히 한국어 금융 데이터와 같은 특수 도메인에서는 범용 모델보다 도메인 적응(Domain Adaptation)을 거친 특화 모델이 유리할 수 있습니다.
이러한 학계의 흐름은 본 프로젝트에서 채택한 'LLM 기반 데이터 생성 → BERT+CRF 하이브리드 모델 구축' 전략이 기술 트렌드와 정확히 부합하며, 실무적으로도 합리적인 방법임을 보여줍니다.
이제 마지막으로, 이렇게 설계된 모델이 전통적인 정규표현식이나 최신 LLM과 비교했을 때 실제로 어떤 성능 차이를 보였는지, 예시를 통해서 확인해보겠습니다.
기술적 의사결정의 핵심은 최신의 기술을 쓰는 것이 아니라, 문제에 가장 적합한 기술을 선택하는 것입니다. 이번 장에서는 우리가 왜 전통적인 정규표현식과 떠오르는 LLM을 두고, BERT-CRF를 선택했는지에 대해서 다뤄보겠습니다.
전통적인 마스킹 시스템은 대부분 정규표현식(Regular Expression)에 의존해 왔습니다. 전화번호나 주민등록번호처럼 형식이 고정된 데이터(Structured Data)를 처리하는 데 있어 정규식만큼 빠르고 확실한 도구는 없기 때문입니다. 하지만 실제 금융 현장의 데이터는 결코 얌전하지 않습니다. 고객이 남긴 거친 비정형 텍스트(Unstructured Text) 앞에서도 정규식은 여전히 유효할까요?
1) 정규식의 두 가지 치명적 약점
첫째, 변칙적 표현에 대한 취약성입니다.
정규식은 '정해진 틀'입니다. 실제 데이터에 빈번한 오타, 의도적인 띄어쓰기, 특수문자 삽입 등이 발생하면, 단 한 글자만 어긋나도 탐지에 실패합니다. 모든 변수(띄어쓰기 경우의 수 등)를 정규식에 다 넣으려다가는 패턴이 기하급수적으로 복잡해져 유지보수가 불가능해집니다.
둘째, 의미 기반 정보의 탐지 불가입니다.
'이름'이나 '상세 주소', '가맹점명'은 정해진 숫자 패턴이 없습니다. "이순신", "을지문덕"이라는 단어는 Context 속에서만 사람 이름으로 기능할 뿐, 글자 자체에는 고유한 규칙이 없습니다. 정규식은 글자 모양만 볼 뿐, 그 의미를 읽지 못합니다.
2) 실제 데이터 비교 : Regex vs NER (Case Study)
반면, 저희가 구현한 하이브리드 접근법(NER 모델)은 주변 단어를 통해 문맥을 읽습니다. 아래는 실제 금융 데이터에서 발생할 수 있는 4가지 대표적인 케이스에 대해 정규식과 NER 모델의 탐지 결과를 비교한 것입니다.
케이스 | 예시 문장 | 정규식 결과 | NER 모델 결과 |
|---|---|---|---|
| "당첨자는 이하늘 님입니다." | - 마스킹 텍스트: 이번 이벤트 당첨자는 이하늘 님입니다. - 발견 개수: 0개 | - 마스킹 텍스트: 이번 이벤트 당첨자는 [이름] 님입니다. - 발견 개수: 1개 * 이하늘 -> [이름] (신뢰도: 0.966) |
(중의성 해결) | "오늘 이하늘 아래 모였습니다." | - 마스킹 텍스트: 오늘 이하늘 아래 우리가 함께 모였습니다. - 발견 개수: 0개 | - 마스킹 텍스트: 오늘 이하늘 아래 우리가 함께 모였습니다. - 발견 개수: 0개 |
| "주민번호는 950101 - 1*** 입니다." | - 마스킹 텍스트: 주민번호는 950101 - 1**** 입니다. - 발견 개수: 0개 | - 마스킹 텍스트: 주민번호는 [주민등록번호] 입니다. - 발견 개수: 1개 * 950101-1**** -> [주민등록번호] (신뢰도: 0.969) |
| "주소는 서울시 강남구 테헤란로 123이고 4층입니다." | - 마스킹 텍스트: 주소는 서울시 강남구 테헤란로 123이고 4층입니다. - 발견 개수: 0개 | - 마스킹 텍스트: 주소는 [상세주소]입니다. - 발견 개수: 1개 * 서울시강남구테헤란로123이고4층 -> [상세주소] (신뢰도: 0.970) |
| "장미 식당에서 2만 원 결제했습니다." | - 마스킹 텍스트: 장미 식당에서 [금액] 원 결제하셨습니다. - 발견 개수: 1개 * 2만 -> [금액] (신뢰도: 1.000) | - 마스킹 텍스트: [가맹점명]에서 [결제금액] 결제하셨습니다. - 발견 개수: 2개 * 장미식당 -> [가맹점명] (신뢰도: 0.529) * 2만원 -> [결제금액] (신뢰도: 0.885) |
3) 결론: 상호 보완적인 하이브리드 전략
위 결과에서 보듯, 문맥 파악이 필요한 영역에서는 NER 모델이 압도적인 성능을 보입니다. 하지만 그렇다고 정규식을 완전히 배제하는 것은 아닙니다.
정규식: 형식이 고정된 주민등록번호, 전화번호, 메일주소 등의 1차 필터링 (속도와 정확성 보장)
NER 모델: 이름, 주소, 가맹점명 등 비정형 텍스트 및 변칙적 패턴 탐지 (유연성과 재현율 보장)
저희는 이 두 가지를 결합한 하이브리드 파이프라인을 구축함으로써, 정규식의 '정확성'과 딥러닝의 '유연성'이라는 두 마리 토끼를 모두 잡을 수 있었습니다.
최근 LLM이 보여주는 문맥 이해력은 놀라운 수준입니다. 프로젝트 초기에는 저희 역시 "그냥 LLM에게 마스킹을 시키면 되지 않을까?"라는 고민을 했습니다. 하지만 하루에도 수억건 이상을 처리하는 금융권의 대용량 로그 시스템이라는 특수한 환경을 고려했을 때, 추론속도(Latency)가 중요했습니다.
1) 1,000자 처리 실험 : Latency의 차이
생성된 금융 상담 로그 1,000자 텍스트를 대상으로 추론 속도를 측정해보았습니다.
LLM (OpenRouter API, gpt-5-mini):
평균 47초

이미지 4. LLM 실험 결과
Hybrid Approach:
평균 0.1초

이미지 5. Hybrid Approach 실험 결과
무려 470배의 속도 차이가 발생했습니다. 하루 수억 건의 로그가 쏟아지는 파이프라인에서 이정도의 Latency는 곧 시스템 마비를 의미합니다. 왜 이런 차이가 발생할까요?
2) 속도의 원인 : Sequential vs Parallel
가장 큰 이유는 모델의 작동방식에 있습니다.
LLM (Autoregressive): "나는" → "서울에" → "산다" 처럼 단어를 하나씩 순차적으로 생성(Sequential Generation)합니다. 1,000자를 출력하려면 모델은 1,000번의 추론을 반복해야 합니다. 문서가 길어질수록 시간은 출력 토큰 수에 비례하여 늘어납니다.
NER (Encoder-only): 반면 BERT 기반 모델은 문장 전체를 한 번에 봅니다. 입력된 텍스트가 길어도 위치 임베딩(Positional Embedding) 사이즈 내의 모든 토큰의 라벨을 단 한 번의 연산으로 동시에 계산합니다.
3) 체급의 차이 : 수백 M vs 수백 B
모델의 크기, 즉 파라미터 수는 배포(Deployment) 환경을 결정짓습니다.
LLM (수십~수천억 파라미터): 최소 수십 GB의 VRAM이 필요하며, 고성능 GPU 서버가 필수적입니다.
NER (수억 파라미터): BERT-base 기준 약 110M개에 불과합니다.
금융권의 On-premise 환경은 컴퓨팅 리소스가 제한적입니다. 딥러닝 모델 하나를 띄우기 위해 수천만원짜리 GPU 서버를 증설하는 것은 비용 효율성 측면에서 불가능에 가깝습니다. 반면 경량화된 NER 모델은 가벼운 GPU만으로도 충분히 운영 가능합니다.
4) API의 딜레마 : 보안과 비용
"그럼 서버 증설 없이 외부 API를 쓰면 되지 않나?"라고 반문할 수 있습니다. 하지만 여기엔 두 가지 장벽이 존재합니다.
보안: 금융 데이터에는 민감한 개인정보가 포함되어 있습니다. 이를 마스킹하기 위해 외부 서버(OpenAI 등)로 원본 데이터를 전송하는 것은 그 자체로 보안 규정 위반입니다.
비용: API는 토큰 단위로 과금됩니다. 테라바이트(TB) 단위의 로그를 매일 처리한다면, 천문학적인 API 비용이 발생하게 됩니다.
정해진 개인정보를 빠르고 가볍게 찾아내는 본 프로젝트의 목적에는 느리고 무거운 LLM보다 통제 가능한 BERT-CRF 모델을 사용한 것이 주어진 제약 사항 안에서 문제를 가장 잘 해결할 수 있는 합리적인 선택이었습니다.
제논의 보안 기술, 그리고 우리가 나아가는 방향
지금까지 제논의 개인정보 마스킹 시스템 구축 여정을 공유해 드렸습니다. 내부 데이터 접근이 제한된 환경에서 '제로베이스 데이터 구축'을 수행하고, NER 태스크의 중요한 문제인 '클래스 불균형'을 다양한 전략으로 해결하며, LLM보다 빠른 실시간 처리를 달성하기까지의 과정을 다뤘습니다.
이 과정에서 개발된 개인정보 마스킹 기술은 실제 제논의 제노스(GenOS) 플랫폼과 원에이전트(OneAgent)에 핵심 보안 모듈로 탑재되어 금융권 및 공공기관 고객사에서 활발히 운영되고 있습니다.
제노스: 생성형 AI 플랫폼 내에서 데이터가 LLM으로 입력되기 전, 혹은 RAG 파이프라인에서 문서를 처리할 때 개인정보를 자동으로 탐지·마스킹하는 안전장치입니다.
원에이전트: AI 에이전트가 고객 데이터를 다루는 과정에서 민감 정보가 외부로 유출되지 않도록 에이전트 레벨의 PII 필터링을 기본 제공합니다.
더 높은 수준의 데이터 보안을 위한 제논의 고민
제논은 여기서 더 나아 산업별(의료, 법률, 공공 등) 특화 보안 모델로의 확장을 준비하고 있습니다. 또한, 온프레미스 환경에 최적화된 모델 경량화와 신규 개인정보 유형에 즉각 대응하는 업데이트 체계를 고도화하고 있습니다.
LLM이 산업 현장에 보편화되는 시대에, "AI가 다루는 모든 데이터 경로는 기본적으로 마스킹되어야 한다(Security by Default)"는 것이 제논의 철학입니다. 개인정보 보호가 선택이 아닌 필수 구성 요소가 되도록, 제논은 기술 개발과 더불어 안전한 AI 활용 표준을 수립하는 데 앞장서겠습니다.
출처
[1] Cheng, J., et al. 2019. "Entity linking for Chinese short texts based on BERT and entity name embeddings." China Conference on Knowledge Graph and Semantic Computing (CCKS). https://conference.bj.bcebos.com/ccks2019/eval/webpage/pdfs/eval_paper_2_1.pdf
[2] AI Hub. 2024. “민간 민원 상담 LLM 사전학습 및 Instruction Tuning 데이터”. https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=71844
[3] Aghakasiri, Kiana, et al. 2025. "Not What the Doctor Ordered: Surveying LLM-based De-identification and Quantifying Clinical Information Loss." Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. https://arxiv.org/abs/2509.14464
[4] Savkin, Maksim, Timur Ionov, and Vasily Konovalov. 2025. "SPY: Enhancing Privacy with Synthetic PII Detection Dataset." Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Workshop). https://aclanthology.org/2025.naacl-srw.23/
[5] Deußer, Tobias, et al. 2025. "Resource-Efficient Anonymization of Textual Data via Knowledge Distillation from Large Language Models." Proceedings of the 31st International Conference on Computational Linguistics: Industry Track. https://aclanthology.org/2025.coling-industry.20/
[6] Zaratiana, Urchade, et al. 2024. "Gliner: Generalist model for named entity recognition using bidirectional transformer." Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). https://aclanthology.org/2024.naacl-long.300/
[7] Hahm, Sungen, et al. 2025. "Thunder-DeID: Accurate and Efficient De-identification Framework for Korean Court Judgments." arXiv preprint arXiv:2506.15266. https://aclanthology.org/2025.findings-emnlp.682/

