목차
AI의 진화 어디까지? 피지컬 AI
AI의 진화 어디까지? 피지컬 AI
Physical AI
Nov 26, 2025

GenOS 기반의 AI 에이전트 전문 업체인 제논: 왜 피지컬 AI에 관심을 갖는가?
제논은 자체 생성형 AI 플랫폼 GenOS를 통해 각 산업 환경에 최적화된 AI 에이전트 기술로 기업의 비즈니스 문제를 해결하는 기업입니다.
뿐만 아니라 원에이전트(OneAgent)라고 불리는 실제 디바이스 제어까지 가능한 브라우저 유즈(Browser Use)와 컴퓨터 유즈 (Computer Use) 기능을 탑재한 액셔너블 AI도 상용화하여 기업에 제공하고 있습니다.
범용적 AI인 오픈AI의 ChatGPT 출시 이후 불과 3년 만에 시장은 멀티모달(Multi-Modal)과 에이젠틱 AI(Agentic AI)로의 확장을 넘어 액셔너블 AI로 진화했으며 현재는 피지컬 AI(Physical AI)로의 발전을 전망하고 있습니다. 이러한 흐름에 발맞춰, 제논은 차세대 AI 기술을 통해 앞서 언급한 디지털 세상을 넘어 우리가 살아가는 물리적인 세상에서의 비즈니스 문제를 해결하고자 합니다.
피지컬 AI 시리즈의 시작인 이번 포스트에서는 오는 12월 네 번째 AIXperience Day 행사에서 공개될 제논의 2026년도 로드맵에 앞서, 피지컬 AI의 기본 개념과 구성요소에 대해 다뤄보려 합니다.
제논은 자체 생성형 AI 플랫폼 GenOS를 통해 각 산업 환경에 최적화된 AI 에이전트 기술로 기업의 비즈니스 문제를 해결하는 기업입니다.
뿐만 아니라 원에이전트(OneAgent)라고 불리는 실제 디바이스 제어까지 가능한 브라우저 유즈(Browser Use)와 컴퓨터 유즈 (Computer Use) 기능을 탑재한 액셔너블 AI도 상용화하여 기업에 제공하고 있습니다.
범용적 AI인 오픈AI의 ChatGPT 출시 이후 불과 3년 만에 시장은 멀티모달(Multi-Modal)과 에이젠틱 AI(Agentic AI)로의 확장을 넘어 액셔너블 AI로 진화했으며 현재는 피지컬 AI(Physical AI)로의 발전을 전망하고 있습니다. 이러한 흐름에 발맞춰, 제논은 차세대 AI 기술을 통해 앞서 언급한 디지털 세상을 넘어 우리가 살아가는 물리적인 세상에서의 비즈니스 문제를 해결하고자 합니다.
피지컬 AI 시리즈의 시작인 이번 포스트에서는 오는 12월 네 번째 AIXperience Day 행사에서 공개될 제논의 2026년도 로드맵에 앞서, 피지컬 AI의 기본 개념과 구성요소에 대해 다뤄보려 합니다.
1. 피지컬 AI: 디지털을 넘어 물리 세계로
지금까지 생성형 AI의 주요 서비스는 챗봇과 이를 활용한 에이전트로서 디지털 세계(Digital World) 안에서만 작동하는 형태로 머물러 있었습니다. 반면 피지컬 AI는 이러한 한계를 넘어, 자율주행차, 로봇, 스마트 공장과 같이 시스템 속에서 단순히 사물만 인식하는 것이 아닌, 사람의 행동·의도·맥락을 이해하며 협력할 수 있는 잠재력을 갖추고 있습니다.
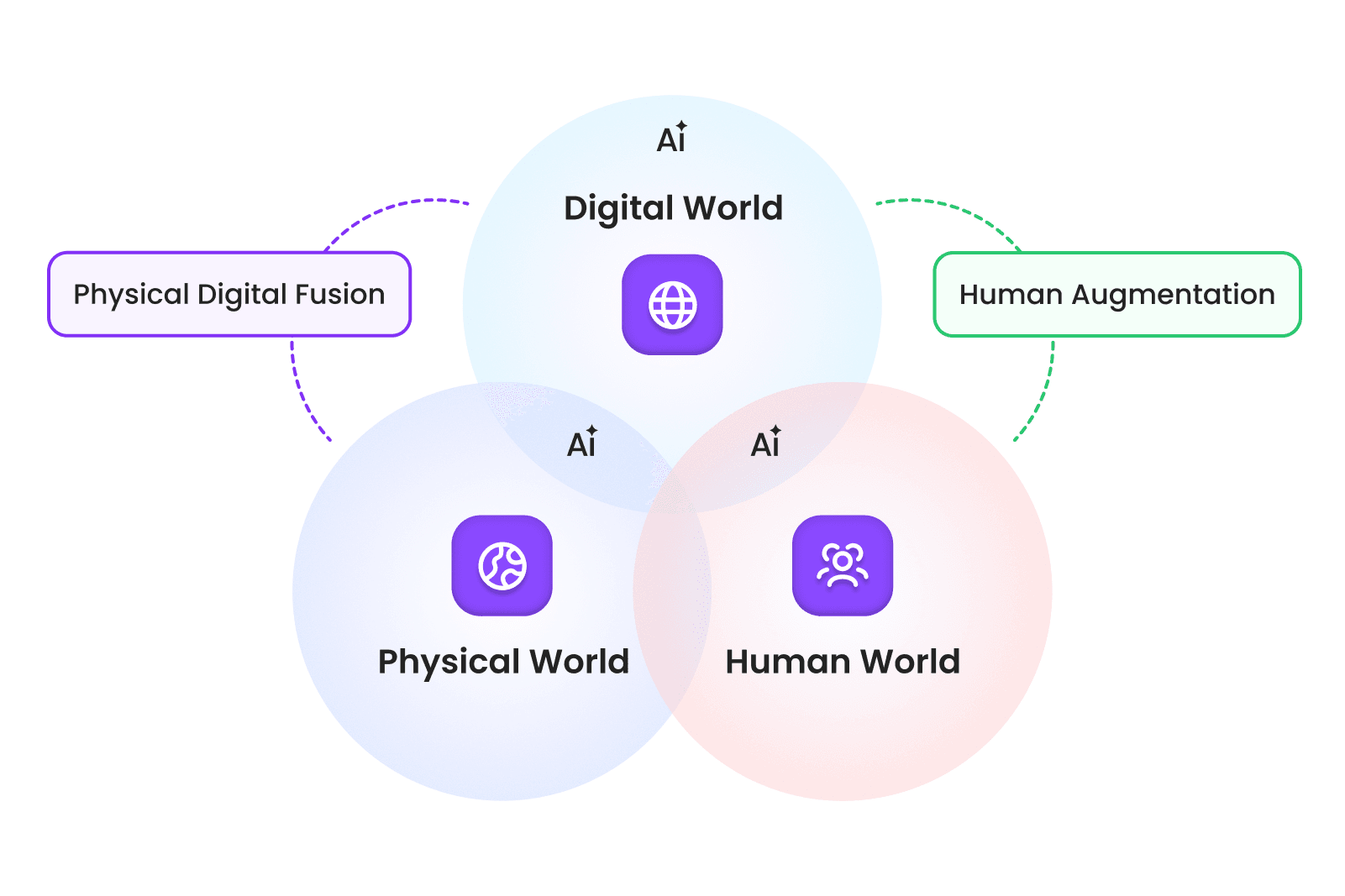
이미지 1. 물리·디지털·휴먼 세계를 잇는 피지컬 AI (제논 재구성). 출처: Nokia Bell Labs
피지컬 AI는 기존 규칙 기반 제어, 기계학습, 딥러닝 기반 모델처럼 정해진 규칙이나 제한된 학습 환경에 머무르지 않고, 생성형 AI의 유연한 추론 능력을 바탕으로 다양한 환경 변화, 복잡한 센서 입력, 그리고 사람의 다양한 행동 패턴까지 폭넓게 대응할 수 있습니다. 아직 초기 단계 수준이지만, 이 능력을 바탕으로 화면 속 디지털 도우미를 넘어, 실제 공간에서 함께 활동하는 파트너로 확장되고 있습니다.
현대차와 BMW 사례를 통해 제조 공장에서 피지컬 AI를 통해 각 기업이 제시하고 있는 비전과 인간과의 협업 파트너로써 어떻게 작동하고 있는지를 확인할 수 있습니다.
현대자동차 그룹은 기계가 인간을 대체하는 것이 아닌, 인간과 기계가 상호 보완적으로 협력하는 생산 체계를 지향하는 다크 팩토리 247(Dark Factory 247, DF247)에 대한 비전을 밝힌 바 있습니다. 피지컬 AI를 통해 기존 자동화가 어려웠던 비정형 부품 조립과 물류 자율화, 디지털 트윈 기반 생산 제어를 구현함으로써 작업자를 위험하고 반복적인 노동에서 해방시키고, 관리와 기획 등 더 고차원적인 역할을 수행할 수 있도록 하는 방향으로 발전하고 있습니다[1].

이미지 2. 미국 조지아주의 현대차그룹 메타플랜트 아메리카(HMGMA) 공장의 모습. 출처: 세계일보[2]
BMW는 실제 X3 생산 라인에 휴머노이드 로봇 피규어02를 투입하여 인간과 협력하는 새로운 생산 방식을 도입했습니다. 이 로봇은 무거운 금속 패널 운반 및 조립 작업을 수행하며 약 3만 대의 차량 생산에 직접적으로 기여했습니다. 이는 로봇이 단순 시연을 넘어 실질적인 까다로운 공정 자동화와 생산성 향상을 이끌었음을 보여줍니다[3].

이미지 3. 피규어02가 BMW 공장에서 작업하는 모습. 출처: 지디넷코리아[3]
지금까지 생성형 AI의 주요 서비스는 챗봇과 이를 활용한 에이전트로서 디지털 세계(Digital World) 안에서만 작동하는 형태로 머물러 있었습니다. 반면 피지컬 AI는 이러한 한계를 넘어, 자율주행차, 로봇, 스마트 공장과 같이 시스템 속에서 단순히 사물만 인식하는 것이 아닌, 사람의 행동·의도·맥락을 이해하며 협력할 수 있는 잠재력을 갖추고 있습니다.
이미지 1. 물리·디지털·휴먼 세계를 잇는 피지컬 AI (제논 재구성). 출처: Nokia Bell Labs
피지컬 AI는 기존 규칙 기반 제어, 기계학습, 딥러닝 기반 모델처럼 정해진 규칙이나 제한된 학습 환경에 머무르지 않고, 생성형 AI의 유연한 추론 능력을 바탕으로 다양한 환경 변화, 복잡한 센서 입력, 그리고 사람의 다양한 행동 패턴까지 폭넓게 대응할 수 있습니다. 아직 초기 단계 수준이지만, 이 능력을 바탕으로 화면 속 디지털 도우미를 넘어, 실제 공간에서 함께 활동하는 파트너로 확장되고 있습니다.
현대차와 BMW 사례를 통해 제조 공장에서 피지컬 AI를 통해 각 기업이 제시하고 있는 비전과 인간과의 협업 파트너로써 어떻게 작동하고 있는지를 확인할 수 있습니다.
현대자동차 그룹은 기계가 인간을 대체하는 것이 아닌, 인간과 기계가 상호 보완적으로 협력하는 생산 체계를 지향하는 다크 팩토리 247(Dark Factory 247, DF247)에 대한 비전을 밝힌 바 있습니다. 피지컬 AI를 통해 기존 자동화가 어려웠던 비정형 부품 조립과 물류 자율화, 디지털 트윈 기반 생산 제어를 구현함으로써 작업자를 위험하고 반복적인 노동에서 해방시키고, 관리와 기획 등 더 고차원적인 역할을 수행할 수 있도록 하는 방향으로 발전하고 있습니다[1].
이미지 2. 미국 조지아주의 현대차그룹 메타플랜트 아메리카(HMGMA) 공장의 모습. 출처: 세계일보[2]
BMW는 실제 X3 생산 라인에 휴머노이드 로봇 피규어02를 투입하여 인간과 협력하는 새로운 생산 방식을 도입했습니다. 이 로봇은 무거운 금속 패널 운반 및 조립 작업을 수행하며 약 3만 대의 차량 생산에 직접적으로 기여했습니다. 이는 로봇이 단순 시연을 넘어 실질적인 까다로운 공정 자동화와 생산성 향상을 이끌었음을 보여줍니다[3].
이미지 3. 피규어02가 BMW 공장에서 작업하는 모습. 출처: 지디넷코리아[3]
2. 피지컬 AI를 구성의 주축: 환경(Environment)과 에이전트(Agent)
그렇다면 피지컬 AI를 통해 생산성을 올리고 비즈니스 문제를 해결하기 위해선 기술적으로 어떤 게 필요할까요?
피지컬 AI를 비즈니스에 도입하기 위해서는 환경과 에이전트 두 가지 요소가 필요합니다.
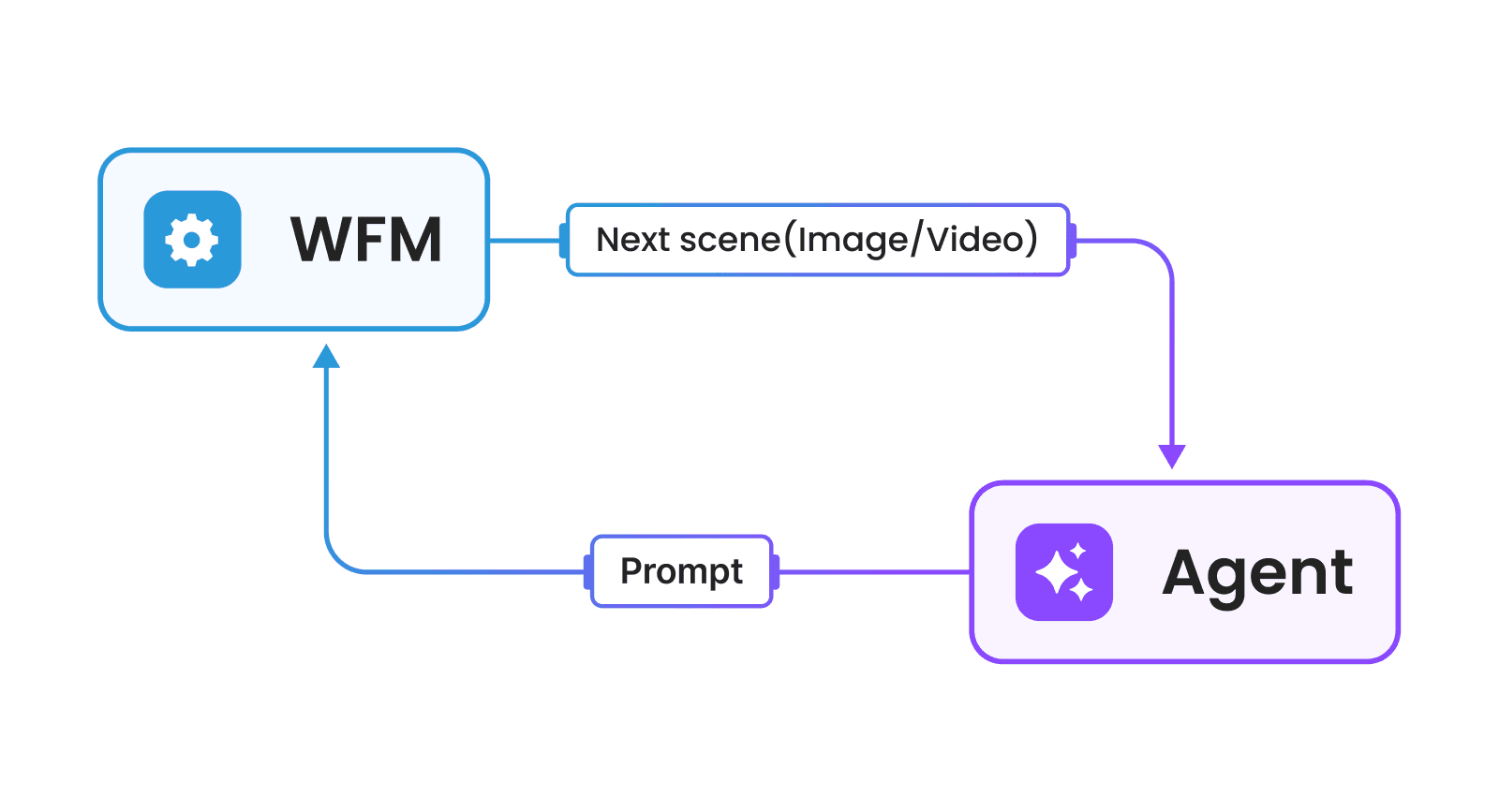
이미지 4. 환경과 에이전트. 출처: 제논
여기서 환경은 에이전트가 인지하고 행동할 공간을 의미합니다. 에이전트의 무대가 되는 환경은 물리적 환경(Physical Environment)과 이를 디지털 트윈(Digital Twin)을 통해 모사한 디지털 환경(Digital Environment)으로 구성됩니다. 물리적 환경의 경우 실제 로봇 등이 활동하는 환경으로 에이전트를 평가하고 활용하는 무대가 됩니다. 반면, 디지털 환경의 경우 가상의 공간을 통해 에이전트에 신호를 주고 에이전트가 제공하는 행동에 반응하는 환경으로 에이전트를 학습하기 위한 무대가 됩니다.
에이전트는 앞서 설명한 환경과 상호작용 하여 환경으로부터 정보를 얻고 환경에 대해 행동하는 AI 모델이 됩니다. 휴머노이드, 로봇팔, 4족 보행로봇 등의 로봇은 센서를 통해 세상으로부터 정보를 인식하고 모터 제어를 통해 세상에 행동하는 인간의 뇌와 같은 역할을 수행하는 지능 시스템으로서 동작합니다. 이는 최근 일반적으로 사용되는 용어인 AI 에이전트와 차이가 있습니다. 같은 에이전트라는 용어를 사용하지만, 본 포스트에서 설명하는 에이전트는 환경과 상호작용에 초점이 맞춰져 있고, AI 에이전트의 경우 메모리(Memory), 도구 호출(Tool Calling), 검색 증강 생성(Retrieval-Augmented Generation, RAG) 등의 기능을 수행하는 언어 모델(Language Model)을 말합니다.
그렇다면 피지컬 AI를 통해 생산성을 올리고 비즈니스 문제를 해결하기 위해선 기술적으로 어떤 게 필요할까요?
피지컬 AI를 비즈니스에 도입하기 위해서는 환경과 에이전트 두 가지 요소가 필요합니다.
이미지 4. 환경과 에이전트. 출처: 제논
여기서 환경은 에이전트가 인지하고 행동할 공간을 의미합니다. 에이전트의 무대가 되는 환경은 물리적 환경(Physical Environment)과 이를 디지털 트윈(Digital Twin)을 통해 모사한 디지털 환경(Digital Environment)으로 구성됩니다. 물리적 환경의 경우 실제 로봇 등이 활동하는 환경으로 에이전트를 평가하고 활용하는 무대가 됩니다. 반면, 디지털 환경의 경우 가상의 공간을 통해 에이전트에 신호를 주고 에이전트가 제공하는 행동에 반응하는 환경으로 에이전트를 학습하기 위한 무대가 됩니다.
에이전트는 앞서 설명한 환경과 상호작용 하여 환경으로부터 정보를 얻고 환경에 대해 행동하는 AI 모델이 됩니다. 휴머노이드, 로봇팔, 4족 보행로봇 등의 로봇은 센서를 통해 세상으로부터 정보를 인식하고 모터 제어를 통해 세상에 행동하는 인간의 뇌와 같은 역할을 수행하는 지능 시스템으로서 동작합니다. 이는 최근 일반적으로 사용되는 용어인 AI 에이전트와 차이가 있습니다. 같은 에이전트라는 용어를 사용하지만, 본 포스트에서 설명하는 에이전트는 환경과 상호작용에 초점이 맞춰져 있고, AI 에이전트의 경우 메모리(Memory), 도구 호출(Tool Calling), 검색 증강 생성(Retrieval-Augmented Generation, RAG) 등의 기능을 수행하는 언어 모델(Language Model)을 말합니다.
2.1 에이전트 학습을 위한 두 가지 환경: WFM, 시뮬레이션
앞서 설명한 에이전트의 학습을 위한 무대가 되는 디지털 환경을 구현하기 위해 현 시점에서 선택되는 방식은 크게 최신의 WFM(World Foundation Model)과 비교적 전통적인 시뮬레이션(Simulation, SIM) 방식이 있습니다.
앞서 설명한 에이전트의 학습을 위한 무대가 되는 디지털 환경을 구현하기 위해 현 시점에서 선택되는 방식은 크게 최신의 WFM(World Foundation Model)과 비교적 전통적인 시뮬레이션(Simulation, SIM) 방식이 있습니다.
💡 WFM (World Foundation Model)란?
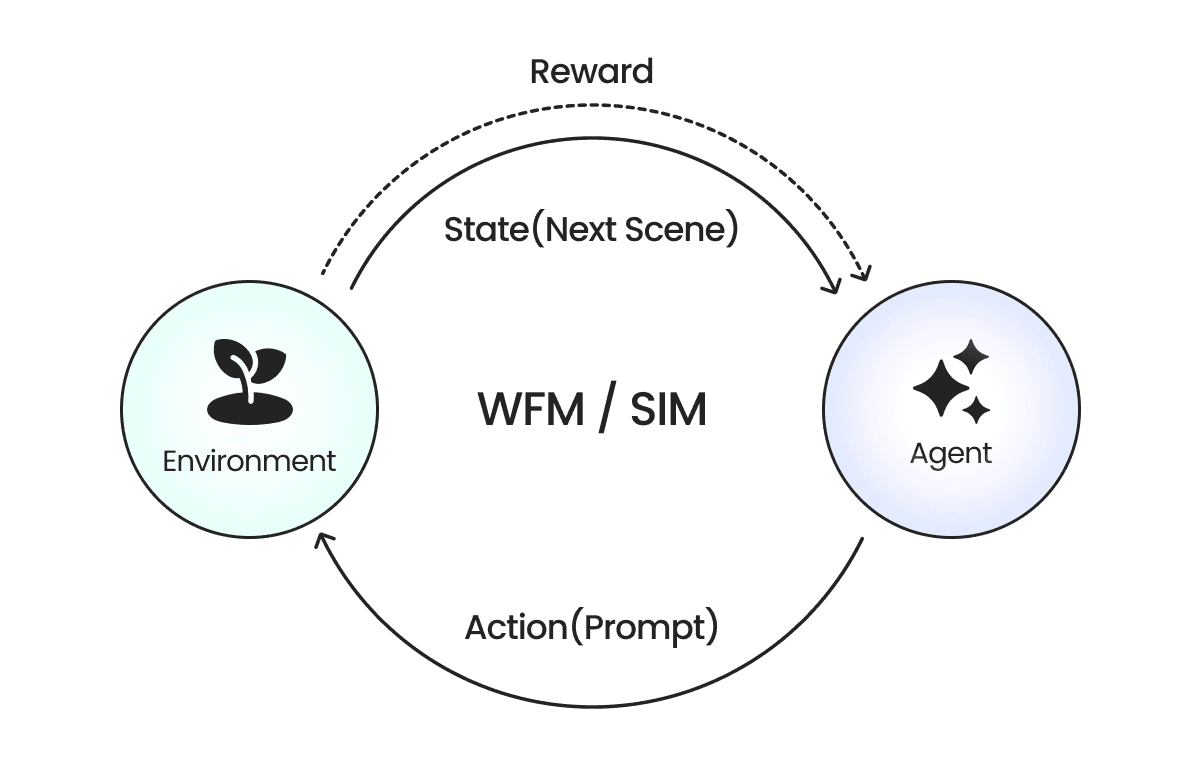
이미지 5. WFM과 에이전트 간 상호작용. 출처: 제논
WFM은 이미지, 영상 등 프롬프트를 입력받아 다음 상황(Next Scene)을 예측하여 보여주는 AI 모델입니다. WFM이 여러 기관에서 지금 이 순간에도 계속 나오고 있는 상황이지만, WFM을 설명하는 가장 기본적인 개념은 아래와 같습니다. 에이전트 혹은 인간으로부터 전달받은 이미지, 영상에 대해 프롬프트(Prompt)를 기반으로 다음 상황(N Frames)에 대해 예측해서 제공하는 모델입니다.
에이전트는 WFM을 기반으로 학습할 시 전달받은 현재 상황에 대해 프롬프트(행동)를 제공하며, 이 프롬프트를 기반으로 WFM이 다음 상황을 에이전트에게 보여주는 방식입니다.
현재까지 시장에 나와 있는 대표적인 WFM인 엔비디아 코스모스(NVIDIA Cosmos)[4], 제네시스(Genesis)[5], PhysX-Anything[6], Marble[7]은 공통적으로 VLT(Vision Language Temporal) 기반의 멀티모달 학습 구조를 따릅니다. 이미지, 비디오, 텍스트 프롬프트를 학습하고 각각 이미지 처리와 텍스트 처리 토크나이저(Tokenizer)를 통해 토큰 형태로 변환되어 임베딩됩니다.
이 과정을 통해 서로 다른 모달 데이터가 하나의 시퀀스로 통합되어 모델이 장면 이해, 예측, 생성 작업을 일관된 방식으로 수행할 수 있습니다.
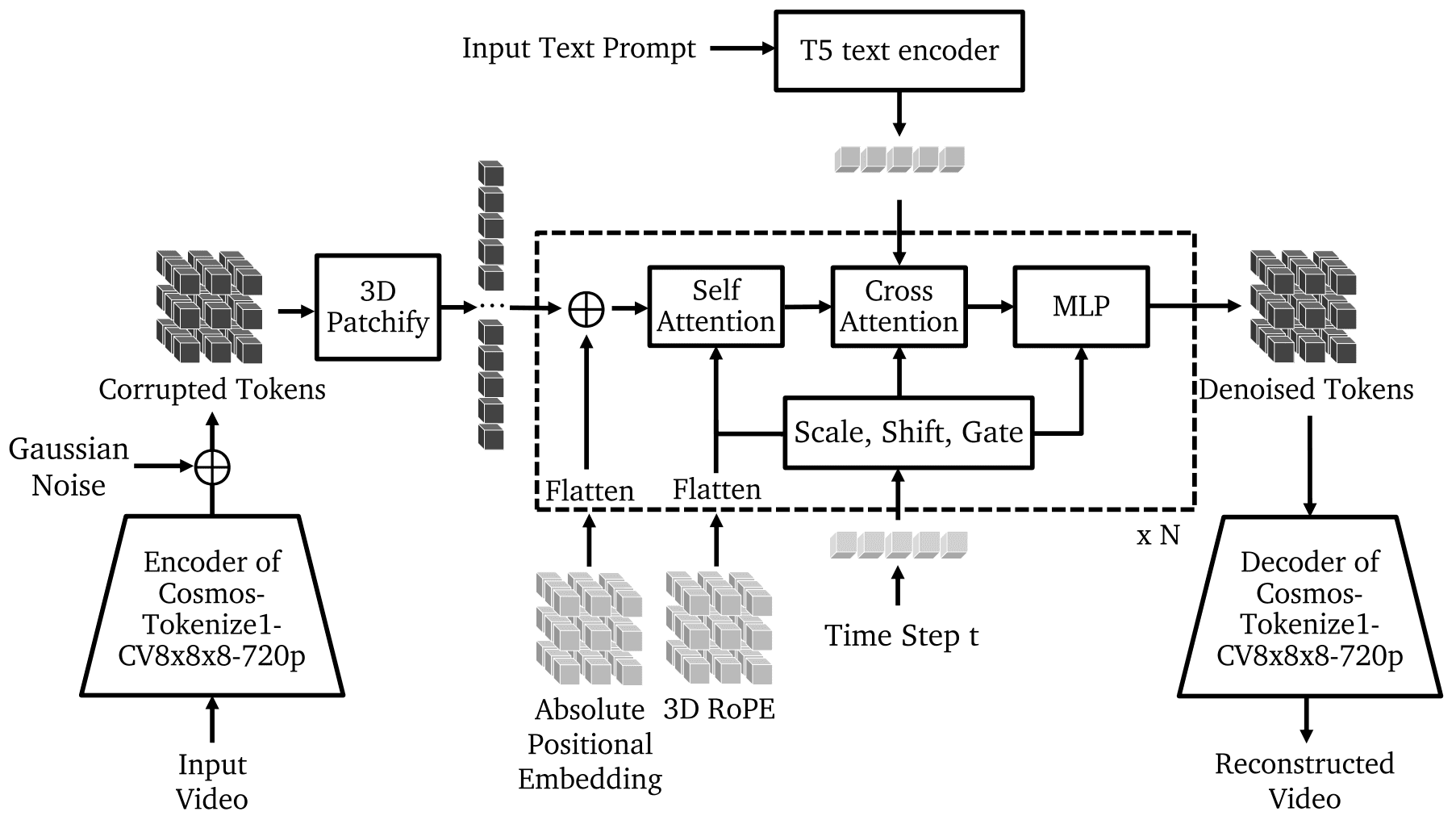
이미지 6. Cosmos-Predict 모델의 구조. 출처: 엔비디아[4]
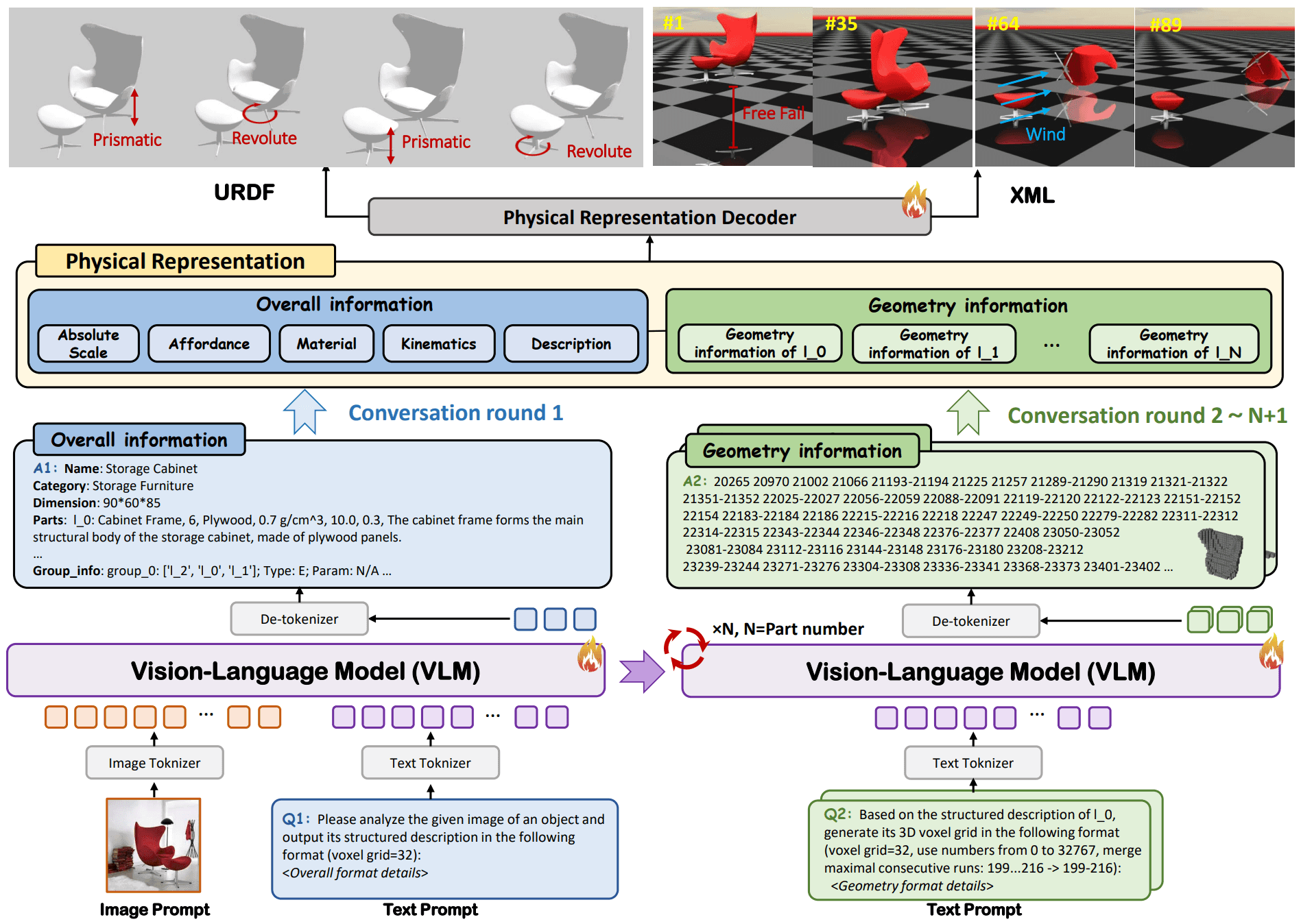
이미지 7. PhysX-Anything 모델의 구조. 출처: S-Lab[6]
표 1. 대표적인 WFM 비교표
구분 | Cosmos-Predict[4] | Genesis[5] | PhysX-Anything[6] | Marble[7] |
|---|---|---|---|---|
입력 | 텍스트·이미지·비디오 | 자연어 프롬프트 | 단일 이미지 + 텍스트(조건) |
|
출력 | 고해상도 이미지·비디오 | 3D Scenes, Policy | URDF/XML 기반 3D Asset | 이미지, 비디오, Gaussian Splats, Mesh |
특징 |
|
|
|
|
이미지 5. WFM과 에이전트 간 상호작용. 출처: 제논
WFM은 이미지, 영상 등 프롬프트를 입력받아 다음 상황(Next Scene)을 예측하여 보여주는 AI 모델입니다. WFM이 여러 기관에서 지금 이 순간에도 계속 나오고 있는 상황이지만, WFM을 설명하는 가장 기본적인 개념은 아래와 같습니다. 에이전트 혹은 인간으로부터 전달받은 이미지, 영상에 대해 프롬프트(Prompt)를 기반으로 다음 상황(N Frames)에 대해 예측해서 제공하는 모델입니다.
에이전트는 WFM을 기반으로 학습할 시 전달받은 현재 상황에 대해 프롬프트(행동)를 제공하며, 이 프롬프트를 기반으로 WFM이 다음 상황을 에이전트에게 보여주는 방식입니다.
현재까지 시장에 나와 있는 대표적인 WFM인 엔비디아 코스모스(NVIDIA Cosmos)[4], 제네시스(Genesis)[5], PhysX-Anything[6], Marble[7]은 공통적으로 VLT(Vision Language Temporal) 기반의 멀티모달 학습 구조를 따릅니다. 이미지, 비디오, 텍스트 프롬프트를 학습하고 각각 이미지 처리와 텍스트 처리 토크나이저(Tokenizer)를 통해 토큰 형태로 변환되어 임베딩됩니다.
이 과정을 통해 서로 다른 모달 데이터가 하나의 시퀀스로 통합되어 모델이 장면 이해, 예측, 생성 작업을 일관된 방식으로 수행할 수 있습니다.
이미지 6. Cosmos-Predict 모델의 구조. 출처: 엔비디아[4]
이미지 7. PhysX-Anything 모델의 구조. 출처: S-Lab[6]
표 1. 대표적인 WFM 비교표
구분 | Cosmos-Predict[4] | Genesis[5] | PhysX-Anything[6] | Marble[7] |
|---|---|---|---|---|
입력 | 텍스트·이미지·비디오 | 자연어 프롬프트 | 단일 이미지 + 텍스트(조건) |
|
출력 | 고해상도 이미지·비디오 | 3D Scenes, Policy | URDF/XML 기반 3D Asset | 이미지, 비디오, Gaussian Splats, Mesh |
특징 |
|
|
|
|
💡 시뮬레이션(Simulation, SIM)이란?

이미지 8. NVIDIA Isaac Sim. 출처: 엔비디아[8]
반면, NVIDIA Isaac Sim으로 대표되는 시뮬레이션은 물리 엔진을 중심으로 중력, 재질별 특성에 기반한 가상의 환경을 제공하는 데 초점을 맞춥니다. 이 환경에서 에이전트 혹은 사용자는 제공된 객체에 부착된 센서에서 인식되는 값을 확인하고, 제공된 모터 제어를 통해 환경 혹은 다른 객체와 상호작용에 대한 결과를 테스트 및 예측해 볼 수 있습니다. 더 나아가 디지털 트윈을 통합하여, 실시간 데이터 기반으로 공장 시스템의 미래 동작을 예측하고, 고장 가능성을 사전에 진단이 가능한 스마트 팩토리의 환경으로써 활용이 가능합니다.
특히 비전에 대한 예측 위주로 제공하는 WFM과는 달리 사용자가 원하는 레이더(RADAR), 라이다(LiDAR)와 같은 센서(Sensor)를 추가로 부착하여 센서 퓨젼(Sensor Fusion) 환경에서의 테스트를 수행해 볼 수 있고, 로봇 운영체제(Robot Operating System**,** ROS/ROS2)와의 연동을 통해 실제 로봇 플랫폼(Robot Platform)과 유사한 환경에서 테스트와 학습을 수행할 수 있다는 장점이 있습니다.
표 2. 시뮬레이션을 구현할 수 있는 도구 종류와 특징 (제논 재구성). 출처: IEEE/ASME Transactions on Mechatronics [9]
항목 | Isaac Sim[8] | Gazebo[10] | Unity[11] | AirSim[12] |
|---|---|---|---|---|
물리 엔진 | PhysX | ODE, Bullet, Simbody, DART | Custom | Custom(Unreal/Unity 내장) |
시각화 기술 | RTX Renderer | OGRE 2.x / Vulkan / OpenGL | Unity Render Pipeline | Unity Render Pipeline (Unity) Nanite + Lumen (UE5) |
포토리얼리즘 | O | X | O | O |
ROS | O | O | O | O |
병렬 가능 여부 | O | O | O | O |
주요 활용 대상 | 휴머노이드, 산업용 로봇 팔, 이족 로봇 | 로봇 팔 | 게임 AI, 드론 | 드론, 자율주행차 |
특징 | - 고품질 포토리얼리즘 렌더링 | - 오픈소스 기반 | - 게임 엔진 기반의 우수한 시각화 | - 드론(PX4/ArduPilot) 특화 |
이미지 8. NVIDIA Isaac Sim. 출처: 엔비디아[8]
반면, NVIDIA Isaac Sim으로 대표되는 시뮬레이션은 물리 엔진을 중심으로 중력, 재질별 특성에 기반한 가상의 환경을 제공하는 데 초점을 맞춥니다. 이 환경에서 에이전트 혹은 사용자는 제공된 객체에 부착된 센서에서 인식되는 값을 확인하고, 제공된 모터 제어를 통해 환경 혹은 다른 객체와 상호작용에 대한 결과를 테스트 및 예측해 볼 수 있습니다. 더 나아가 디지털 트윈을 통합하여, 실시간 데이터 기반으로 공장 시스템의 미래 동작을 예측하고, 고장 가능성을 사전에 진단이 가능한 스마트 팩토리의 환경으로써 활용이 가능합니다.
특히 비전에 대한 예측 위주로 제공하는 WFM과는 달리 사용자가 원하는 레이더(RADAR), 라이다(LiDAR)와 같은 센서(Sensor)를 추가로 부착하여 센서 퓨젼(Sensor Fusion) 환경에서의 테스트를 수행해 볼 수 있고, 로봇 운영체제(Robot Operating System**,** ROS/ROS2)와의 연동을 통해 실제 로봇 플랫폼(Robot Platform)과 유사한 환경에서 테스트와 학습을 수행할 수 있다는 장점이 있습니다.
표 2. 시뮬레이션을 구현할 수 있는 도구 종류와 특징 (제논 재구성). 출처: IEEE/ASME Transactions on Mechatronics [9]
항목 | Isaac Sim[8] | Gazebo[10] | Unity[11] | AirSim[12] |
|---|---|---|---|---|
물리 엔진 | PhysX | ODE, Bullet, Simbody, DART | Custom | Custom(Unreal/Unity 내장) |
시각화 기술 | RTX Renderer | OGRE 2.x / Vulkan / OpenGL | Unity Render Pipeline | Unity Render Pipeline (Unity) Nanite + Lumen (UE5) |
포토리얼리즘 | O | X | O | O |
ROS | O | O | O | O |
병렬 가능 여부 | O | O | O | O |
주요 활용 대상 | 휴머노이드, 산업용 로봇 팔, 이족 로봇 | 로봇 팔 | 게임 AI, 드론 | 드론, 자율주행차 |
특징 | - 고품질 포토리얼리즘 렌더링 | - 오픈소스 기반 | - 게임 엔진 기반의 우수한 시각화 | - 드론(PX4/ArduPilot) 특화 |
2.2 피지컬 AI 에이전트의 두 가지 접근 방법: 엔드 투 엔드, 멀티 에이전트 시스템
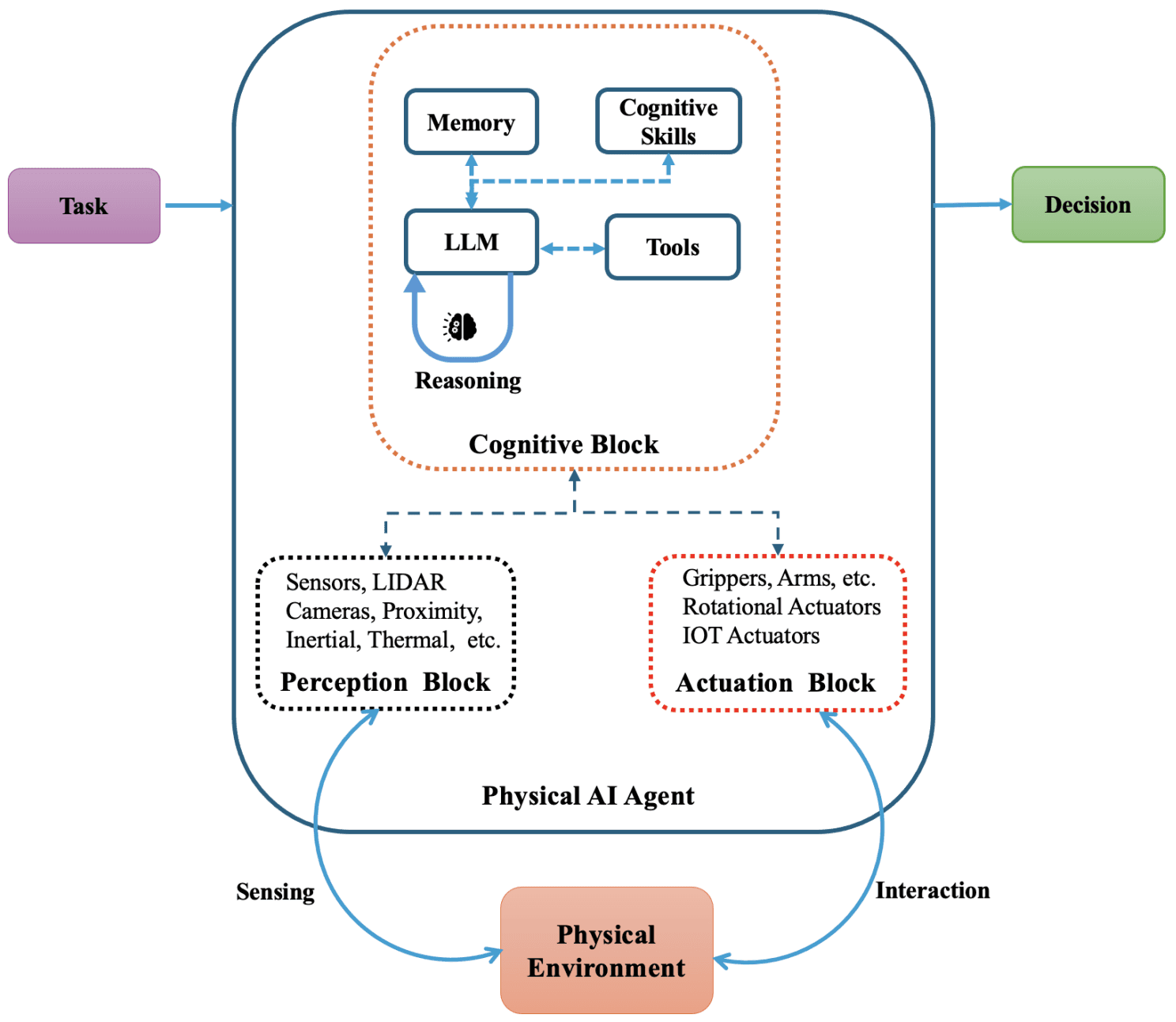
이미지 9. 피지컬 AI 에이전트의 핵심 컴포넌트. 출처: The University of Chicago, USA[13]
피지컬 AI를 구현하기 위한 두 번째 요소인 에이전트는 환경을 인지하고, 판단하며, 행동을 수행하는 지능형 시스템입니다. 에이전트가 로봇·센서·액추에이터와 결합되어 디지털 정보뿐 아니라 실제 물리 환경과 직접 상호작용하게 됩니다.
위 그림은 피지컬 AI 에이전트의 핵심 컴포넌트[13]를 보여줍니다. 작업(Task)이 입력되면 에이전트는 물리 환경을 센싱(Sensing)하여 정보를 수집하고, 내부 과정을 거쳐 최종 결정(Decision)을 내립니다. 이 결정은 다시 물리 환경과의 상호작용(Interaction)으로 이어지며, 이러한 순환 과정을 통해 작업을 수행합니다.
이때 에이전트 내부 과정은 인지(Perception), 판단(Cognition), 제어(Actuation) 총 세 가지 블록으로 구성됩니다.
인지 블록은 에이전트가 주변 환경을 감지하고 이해하는 부분입니다. 카메라(Camera), 라이다, 레이더, 관성 측정 장치(Inertial Measurement Unit, IMU), 사물 인터넷(Internet of Things, IoT) 등의 센서를 통해 공간 구조, 객체 위치, 움직임 같은 실시간 환경 데이터를 수집하고 처리하여 상황을 파악합니다.
판단 블록은 에이전트의 의사결정을 담당하는 부분입니다. 특화된 대형 언어 모델(Large language model, LLM) 및 VLM(Vision-language model)을 기반으로 센서 데이터를 분석하고, 메모리를 통해 과거 경험을 기억하며, 환경 제약을 고려해 작업을 동적으로 계획합니다. 중력, 마찰 같은 물리 법칙을 이해하고, 인지한 정보를 실행 가능한 행동으로 전환하게 됩니다.
제어 블록은 인지 처리 블록의 결정을 물리적 행동으로 실행하는 부분입니다. 로봇 팔, 그리퍼, 유압 시스템, 이동 플랫폼 등의 액추에이터를 통해 정밀한 동작을 수행하여 환경과 상호작용합니다.
이러한 피지컬 AI 에이전트를 실제 로봇에 적용하기 위해서는 두 가지 주요 학습 방법론이 사용됩니다. 하나의 단일 에이전트(모델)로 모든 과정을 처리하는 엔드 투 엔드(End-to-End, E2E) 방식과, 여러 에이전트가 협업하는 멀티 에이전트 시스템(Multi-Agent System, MAS) 방식입니다. 가장 기본적인 멀티 에이전트 시스템구조를 예로 들면, 인지, 판단, 제어 각 블록에 대해 전문화된 에이전트를 적용함으로써 여러 에이전트의 협업을 통해 주어진 작업을 수행합니다.
이미지 9. 피지컬 AI 에이전트의 핵심 컴포넌트. 출처: The University of Chicago, USA[13]
피지컬 AI를 구현하기 위한 두 번째 요소인 에이전트는 환경을 인지하고, 판단하며, 행동을 수행하는 지능형 시스템입니다. 에이전트가 로봇·센서·액추에이터와 결합되어 디지털 정보뿐 아니라 실제 물리 환경과 직접 상호작용하게 됩니다.
위 그림은 피지컬 AI 에이전트의 핵심 컴포넌트[13]를 보여줍니다. 작업(Task)이 입력되면 에이전트는 물리 환경을 센싱(Sensing)하여 정보를 수집하고, 내부 과정을 거쳐 최종 결정(Decision)을 내립니다. 이 결정은 다시 물리 환경과의 상호작용(Interaction)으로 이어지며, 이러한 순환 과정을 통해 작업을 수행합니다.
이때 에이전트 내부 과정은 인지(Perception), 판단(Cognition), 제어(Actuation) 총 세 가지 블록으로 구성됩니다.
인지 블록은 에이전트가 주변 환경을 감지하고 이해하는 부분입니다. 카메라(Camera), 라이다, 레이더, 관성 측정 장치(Inertial Measurement Unit, IMU), 사물 인터넷(Internet of Things, IoT) 등의 센서를 통해 공간 구조, 객체 위치, 움직임 같은 실시간 환경 데이터를 수집하고 처리하여 상황을 파악합니다.
판단 블록은 에이전트의 의사결정을 담당하는 부분입니다. 특화된 대형 언어 모델(Large language model, LLM) 및 VLM(Vision-language model)을 기반으로 센서 데이터를 분석하고, 메모리를 통해 과거 경험을 기억하며, 환경 제약을 고려해 작업을 동적으로 계획합니다. 중력, 마찰 같은 물리 법칙을 이해하고, 인지한 정보를 실행 가능한 행동으로 전환하게 됩니다.
제어 블록은 인지 처리 블록의 결정을 물리적 행동으로 실행하는 부분입니다. 로봇 팔, 그리퍼, 유압 시스템, 이동 플랫폼 등의 액추에이터를 통해 정밀한 동작을 수행하여 환경과 상호작용합니다.
이러한 피지컬 AI 에이전트를 실제 로봇에 적용하기 위해서는 두 가지 주요 학습 방법론이 사용됩니다. 하나의 단일 에이전트(모델)로 모든 과정을 처리하는 엔드 투 엔드(End-to-End, E2E) 방식과, 여러 에이전트가 협업하는 멀티 에이전트 시스템(Multi-Agent System, MAS) 방식입니다. 가장 기본적인 멀티 에이전트 시스템구조를 예로 들면, 인지, 판단, 제어 각 블록에 대해 전문화된 에이전트를 적용함으로써 여러 에이전트의 협업을 통해 주어진 작업을 수행합니다.
💡 엔드 투 엔드(End-to-End, E2E)방식이란?
엔드 투 엔드 모델은 입력에서 출력까지 하나의 통합된 신경망으로 처리하는 방식으로, 피지컬 AI에서는 비전, 언어, 행동을 통합한 VLA(Vision-Language-Action) 모델이 대표적입니다.
최신 VLA 모델들에 대해 아래 표 3.과 같이 분석한 결과 모델들의 공통적인 핵심 기술은 크게 두 가지가 있습니다.
표 3. 최근 VLA 모델 비교표
모델 | 파라미터 | 기술 | 주요 성과 |
|---|---|---|---|
GR00T N1-2B[14] | 2.2B | 이중 아키텍처 구조로 설계된 범용 휴머노이드 로봇 기반 모델 | 시뮬레이션에서 기존 대비 최대 17%p 향상 Closed-loop motor action의 경우 120Hz로 동작 |
OpenVLA[15] | 7B | 97만 개 실제 로봇 시연 데이터 학습 | Diffusion Policy 대비 20.4% 성능 향상 5Hz로 동작 |
EMMA[16] | - | 센서 입력부터 제어 출력까지 하나의 Multimodal LLM으로 처리 | 차량의 Around View 데이터를 input으로 받음(이미지 8장) |
π0[17] | 3.3B | 사전 학습 VLM + Flow matching | 50Hz 실시간 제어 가능 |
OpenVLA-OFT[18] | 7B | 병렬 디코딩 + L1 회귀 | OpenVLA 대비 추론 속도 25-50배 향상 |
3D-CAVLA[19] | - | 3D 공간 정보(Depth) 인식 | LIBERO 98.1% 성공률 |
SmolVLA[20] | 0.5B 미만 | 경량화 아키텍처 | 단일 GPU 학습, 10배 큰 VLA와 비교 가능한 성능 |
첫 번째 기술은 엔비디아(NVIDIA)의 VLA 모델인 GR00T N1[14]에서 확인할 수 있는 액션 청킹(Action Chunking) & 스테이트 인풋(State Input) 입니다.
액션 청킹이란 현재 시점의 단일 행동이 아닌 미래 여러 스텝의 행동 시퀀스를 한 번에 예측하는 기술이며, 스테이트 인풋이란 로봇의 관절 위치와 같은 물리적 상태 정보를 모델의 입력으로 제공하는 것을 의미합니다. 대표적 사례인 GR00T N1은 Eagle-2 VLM과 SigLIP-2 인코더로 이미지를 처리하여 vision-language token embeddings를 생성하고, Diffusion Transformer가 이를 상태(State)와 cross-attention으로 결합하여 미래 H-스텝의 액션 청크(action chunk)를 flow matching 기법으로 생성합니다[14]. 이처럼 시각 인식부터 언어 이해, 행동 생성까지 모든 과정이 하나의 신경망 내에서 엔드 투 엔드로 학습되고 실행됩니다.
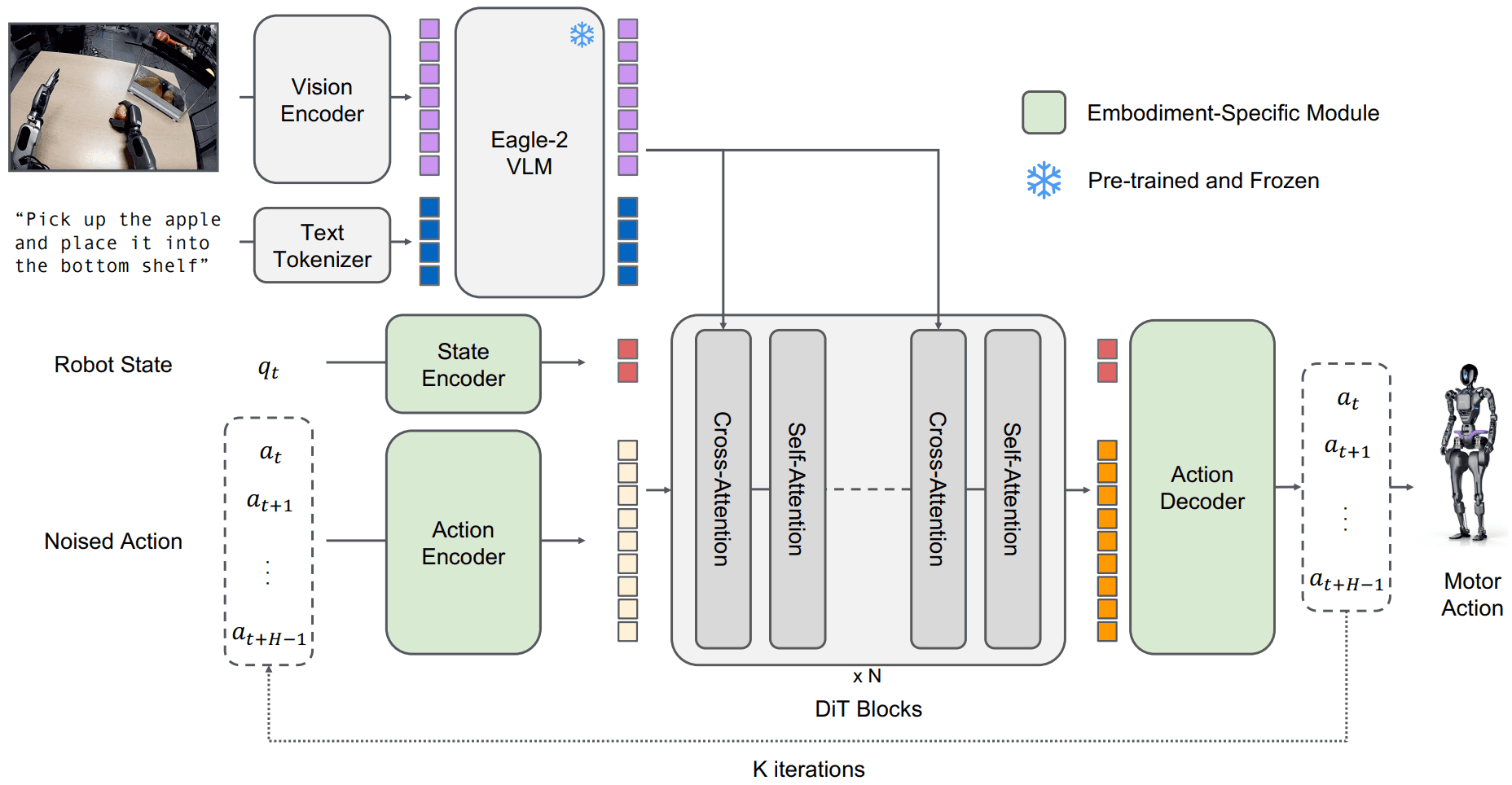
이미지 9. GR00T N1 모델의 구조. 출처: 엔비디아[14]
두 번째 방법은 네이버 AI 랩에서 금번 NeurIPS에 발표한 논문에서 확인할 수 있는 비전 인코더 튜닝(Vision Encoder Tuning)입니다[21]. 최신 VLM 연구에서는 비전 인코더(Vision Encoder)를 학습하는 접근이 피지컬 AI에서도 효과적인 것으로 나옵니다. 네이버 AI 랩의 토큰 병목(Token Bottleneck, ToBo) 방식은 현재 장면을 하나의 병목 토큰(Bottleneck Token)으로 압축한 뒤, 미래 장면의 90% 이상을 가린 상태에서 예측하도록 학습시켜 장면 정보를 보존하는 보수적 요약(conservative summarization)과 시간적 변화 이해(temporal dynamics)를 동시에 달성합니다. 이 기법은 로봇 조작 벤치마크인 Franka Kitchen[22]에서 RSP, CropMAE, SiamMAE 등 기존 SSL(Self-Supervised Learning) 방식 대비 평균 24%p 이상 높은 성능을 보였습니다.

로봇 조작 벤치마크 Franka Kitchen. 출처: UC Berkeley[22]
엔드 투 엔드 모델은 입력에서 출력까지 하나의 통합된 신경망으로 처리하는 방식으로, 피지컬 AI에서는 비전, 언어, 행동을 통합한 VLA(Vision-Language-Action) 모델이 대표적입니다.
최신 VLA 모델들에 대해 아래 표 3.과 같이 분석한 결과 모델들의 공통적인 핵심 기술은 크게 두 가지가 있습니다.
표 3. 최근 VLA 모델 비교표
모델 | 파라미터 | 기술 | 주요 성과 |
|---|---|---|---|
GR00T N1-2B[14] | 2.2B | 이중 아키텍처 구조로 설계된 범용 휴머노이드 로봇 기반 모델 | 시뮬레이션에서 기존 대비 최대 17%p 향상 Closed-loop motor action의 경우 120Hz로 동작 |
OpenVLA[15] | 7B | 97만 개 실제 로봇 시연 데이터 학습 | Diffusion Policy 대비 20.4% 성능 향상 5Hz로 동작 |
EMMA[16] | - | 센서 입력부터 제어 출력까지 하나의 Multimodal LLM으로 처리 | 차량의 Around View 데이터를 input으로 받음(이미지 8장) |
π0[17] | 3.3B | 사전 학습 VLM + Flow matching | 50Hz 실시간 제어 가능 |
OpenVLA-OFT[18] | 7B | 병렬 디코딩 + L1 회귀 | OpenVLA 대비 추론 속도 25-50배 향상 |
3D-CAVLA[19] | - | 3D 공간 정보(Depth) 인식 | LIBERO 98.1% 성공률 |
SmolVLA[20] | 0.5B 미만 | 경량화 아키텍처 | 단일 GPU 학습, 10배 큰 VLA와 비교 가능한 성능 |
첫 번째 기술은 엔비디아(NVIDIA)의 VLA 모델인 GR00T N1[14]에서 확인할 수 있는 액션 청킹(Action Chunking) & 스테이트 인풋(State Input) 입니다.
액션 청킹이란 현재 시점의 단일 행동이 아닌 미래 여러 스텝의 행동 시퀀스를 한 번에 예측하는 기술이며, 스테이트 인풋이란 로봇의 관절 위치와 같은 물리적 상태 정보를 모델의 입력으로 제공하는 것을 의미합니다. 대표적 사례인 GR00T N1은 Eagle-2 VLM과 SigLIP-2 인코더로 이미지를 처리하여 vision-language token embeddings를 생성하고, Diffusion Transformer가 이를 상태(State)와 cross-attention으로 결합하여 미래 H-스텝의 액션 청크(action chunk)를 flow matching 기법으로 생성합니다[14]. 이처럼 시각 인식부터 언어 이해, 행동 생성까지 모든 과정이 하나의 신경망 내에서 엔드 투 엔드로 학습되고 실행됩니다.
이미지 9. GR00T N1 모델의 구조. 출처: 엔비디아[14]
두 번째 방법은 네이버 AI 랩에서 금번 NeurIPS에 발표한 논문에서 확인할 수 있는 비전 인코더 튜닝(Vision Encoder Tuning)입니다[21]. 최신 VLM 연구에서는 비전 인코더(Vision Encoder)를 학습하는 접근이 피지컬 AI에서도 효과적인 것으로 나옵니다. 네이버 AI 랩의 토큰 병목(Token Bottleneck, ToBo) 방식은 현재 장면을 하나의 병목 토큰(Bottleneck Token)으로 압축한 뒤, 미래 장면의 90% 이상을 가린 상태에서 예측하도록 학습시켜 장면 정보를 보존하는 보수적 요약(conservative summarization)과 시간적 변화 이해(temporal dynamics)를 동시에 달성합니다. 이 기법은 로봇 조작 벤치마크인 Franka Kitchen[22]에서 RSP, CropMAE, SiamMAE 등 기존 SSL(Self-Supervised Learning) 방식 대비 평균 24%p 이상 높은 성능을 보였습니다.
로봇 조작 벤치마크 Franka Kitchen. 출처: UC Berkeley[22]
💡 멀티 에이전트 시스템(Multi-Agent System, MAS)이란?
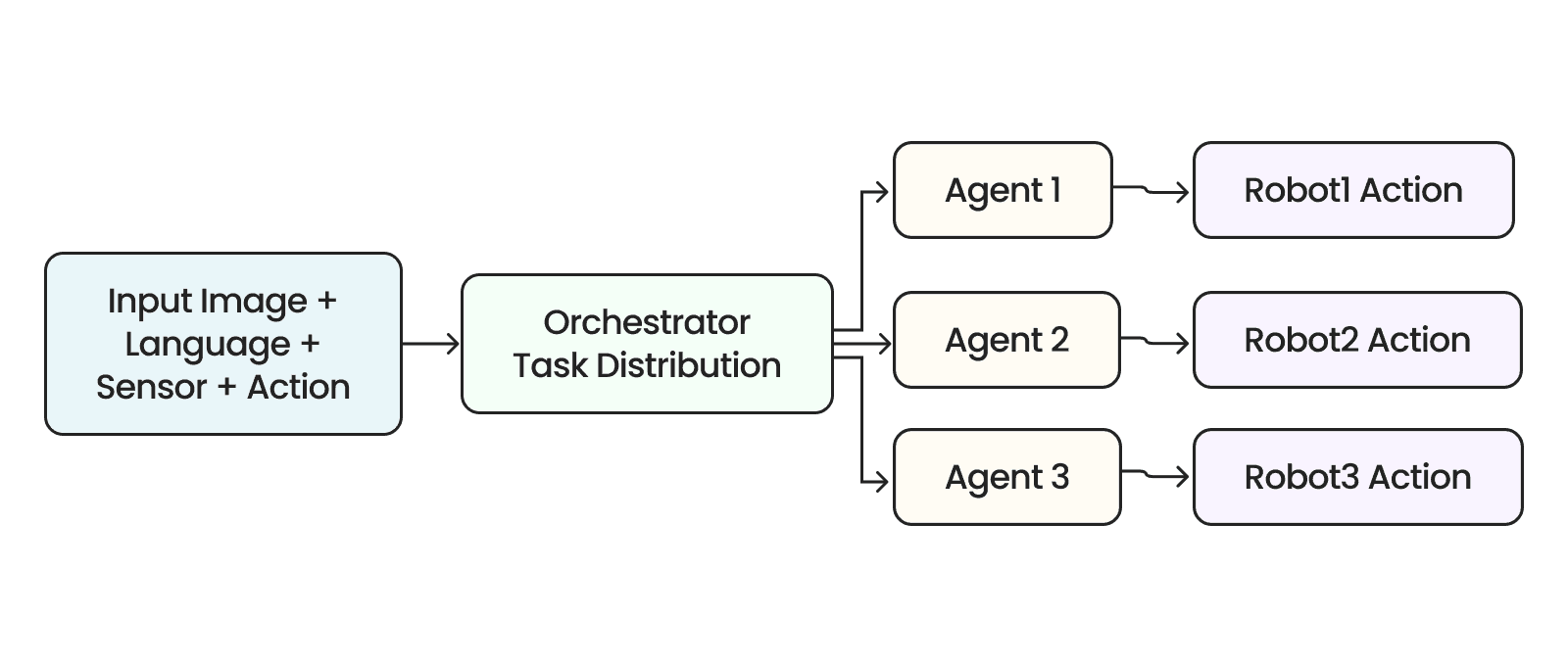
이미지 12. 멀티 에이전트 시스템을 활용한 로봇 오케스트레이션 구조의 예시. 출처: 제논
멀티 에이전트 시스템 방식은 오케스트레이터(Orchestrator)를 중심으로 여러 전문화된 에이전트가 협업하여 공동의 목표를 달성하는 구조입니다. 피지컬 AI에서는 이미지, 언어, 센서 데이터를 포함한 입력이 들어오면 오케스트레이터가 작업을 분석하여 각 전문 에이전트에게 적절히 분배하고, 각 에이전트는 독립적으로 작업을 수행한 뒤 최종적으로 각자의 로봇 행동을 생성합니다.
아직 피지컬 AI에 멀티 에이전트 시스템 구조를 적용한 사례는 보고되지 않았으나, 멀티 에이전트 시스템 구조의 효과는 액셔너블 AI 등 여러 연구에서 확인 가능합니다.
마이크로소프트(Microsoft)의 Magentic-One은 오케스트레이터가 WebSurfer, FileSurfer, Coder, ComputerTerminal 4개 전문 에이전트를 조율하면서 GAIA, AssistantBench, WebArena 벤치마크에서 각각 omne v0.1, SPA→CB (Claude), WebPilot 등 기존 좋은 성능을 낸 시스템들과 비슷한 수준을 보였습니다[23]. 각 구성 요소가 얼마나 중요한지 확인하기 위해 하나씩 제거해 본 결과, 오케스트레이터의 기능을 단순히 어느 에이전트가 다음에 발화할지만 결정하는 식으로 바꾸자 성능이 31% 떨어졌고, Worker 에이전트를 하나만 제거해도 21~39% 성능이 하락했습니다. 이는 멀티 에이전트 시스템의 구조와 적절한 에이전트의 역할 분담이 시스템 전체 성능에 필수적임을 보여줍니다.
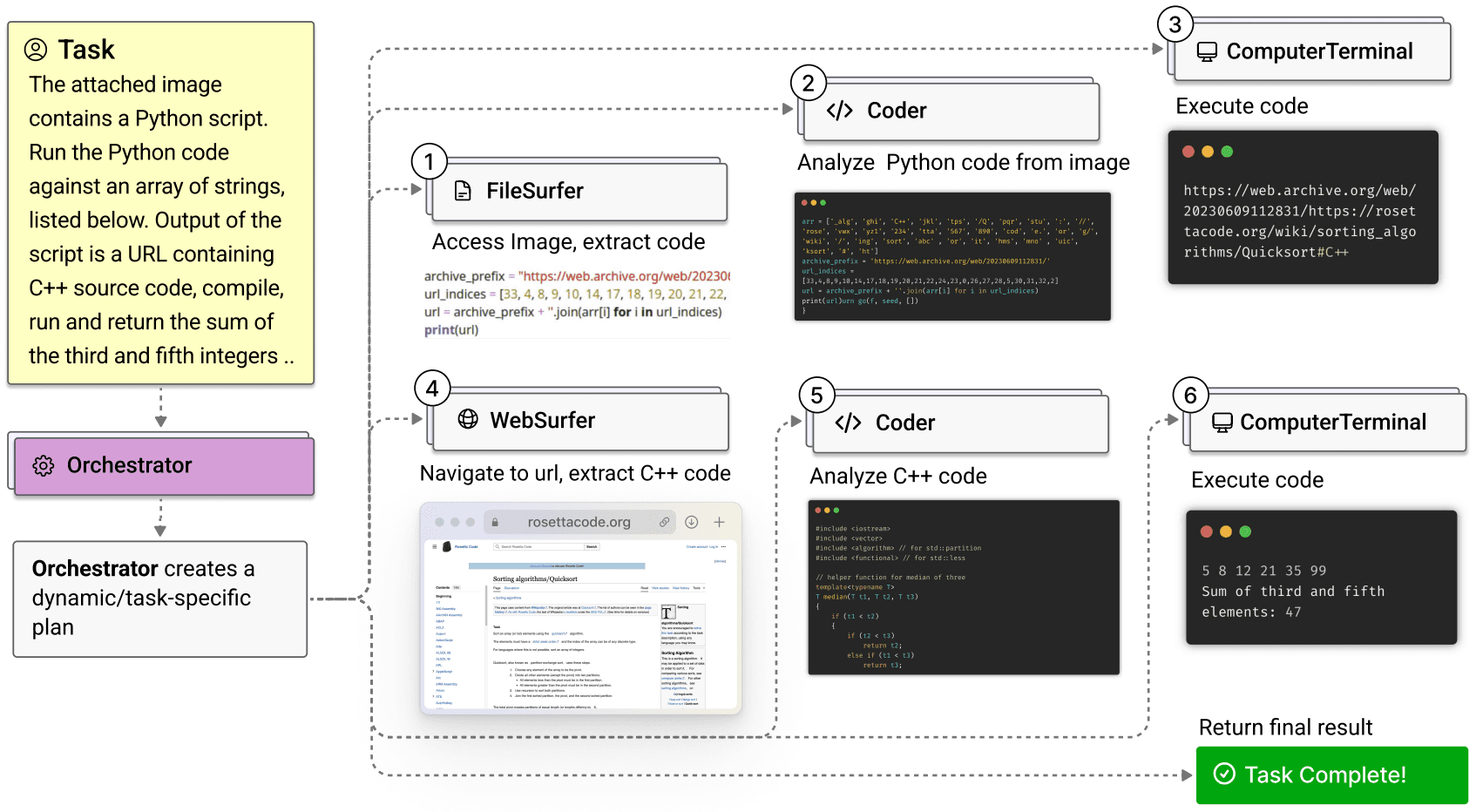
이미지 13. 액셔너블 AI에서의 오케스트레이션 방식 멀티 에이전트 시스템 예시. 출처: 마이크로소프트[23]
또한, Agent0 연구에서는 외부 데이터 없이 자율적으로 학습하는 co-evolution 하는 프레임워크를 제안했습니다[24]. Curriculum Agent가 점점 어려운 문제를 생성하면 Executor Agent가 이를 해결하며 학습하는 구조입니다. 동일한 Qwen3-8B-Base 모델을 사용했을 때, Agent0는 학습하지 않은 기본 모델 대비 18% 향상된 58.2점을 달성했습니다. 또한 단일 모델이 스스로 학습하는 R-Zero 방식(54.7점)보다도 3.5점 높은 성능을 기록했습니다. 이처럼 서로 다른 역할을 맡은 에이전트들이 협업할 때 멀티 에이전트 시스템은 단일 에이전트보다 더 복잡하고 어려운 과제를 처리할 수 있으며, 유연성, 견고성, 확장성 측면에서 강점을 가집니다.
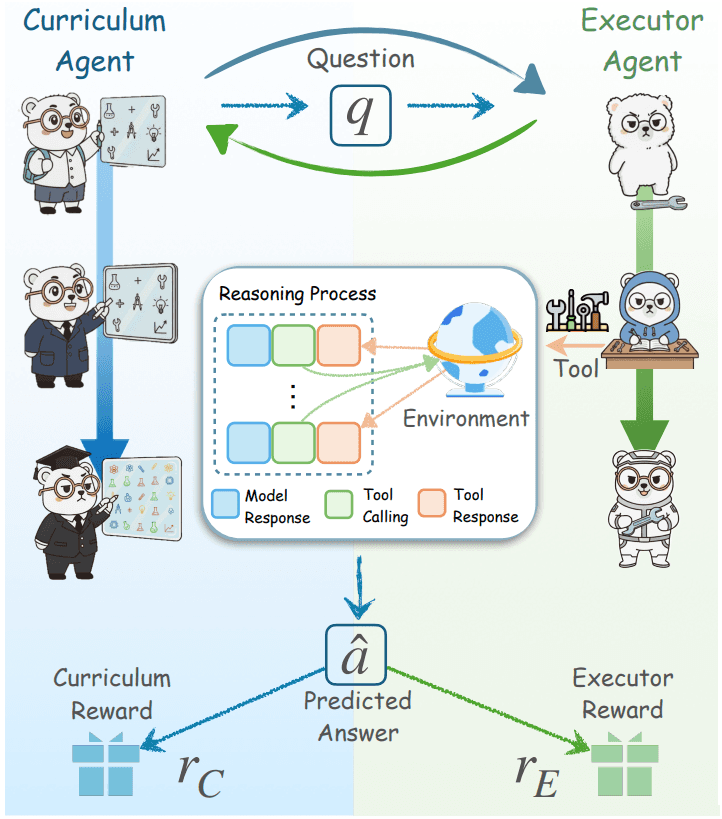
이미지 14. Agent0에서의 Curriculum Agent와 Executor Agent간의 관계. 출처: UNC-Chapel Hill[24]
이미지 12. 멀티 에이전트 시스템을 활용한 로봇 오케스트레이션 구조의 예시. 출처: 제논
멀티 에이전트 시스템 방식은 오케스트레이터(Orchestrator)를 중심으로 여러 전문화된 에이전트가 협업하여 공동의 목표를 달성하는 구조입니다. 피지컬 AI에서는 이미지, 언어, 센서 데이터를 포함한 입력이 들어오면 오케스트레이터가 작업을 분석하여 각 전문 에이전트에게 적절히 분배하고, 각 에이전트는 독립적으로 작업을 수행한 뒤 최종적으로 각자의 로봇 행동을 생성합니다.
아직 피지컬 AI에 멀티 에이전트 시스템 구조를 적용한 사례는 보고되지 않았으나, 멀티 에이전트 시스템 구조의 효과는 액셔너블 AI 등 여러 연구에서 확인 가능합니다.
마이크로소프트(Microsoft)의 Magentic-One은 오케스트레이터가 WebSurfer, FileSurfer, Coder, ComputerTerminal 4개 전문 에이전트를 조율하면서 GAIA, AssistantBench, WebArena 벤치마크에서 각각 omne v0.1, SPA→CB (Claude), WebPilot 등 기존 좋은 성능을 낸 시스템들과 비슷한 수준을 보였습니다[23]. 각 구성 요소가 얼마나 중요한지 확인하기 위해 하나씩 제거해 본 결과, 오케스트레이터의 기능을 단순히 어느 에이전트가 다음에 발화할지만 결정하는 식으로 바꾸자 성능이 31% 떨어졌고, Worker 에이전트를 하나만 제거해도 21~39% 성능이 하락했습니다. 이는 멀티 에이전트 시스템의 구조와 적절한 에이전트의 역할 분담이 시스템 전체 성능에 필수적임을 보여줍니다.
이미지 13. 액셔너블 AI에서의 오케스트레이션 방식 멀티 에이전트 시스템 예시. 출처: 마이크로소프트[23]
또한, Agent0 연구에서는 외부 데이터 없이 자율적으로 학습하는 co-evolution 하는 프레임워크를 제안했습니다[24]. Curriculum Agent가 점점 어려운 문제를 생성하면 Executor Agent가 이를 해결하며 학습하는 구조입니다. 동일한 Qwen3-8B-Base 모델을 사용했을 때, Agent0는 학습하지 않은 기본 모델 대비 18% 향상된 58.2점을 달성했습니다. 또한 단일 모델이 스스로 학습하는 R-Zero 방식(54.7점)보다도 3.5점 높은 성능을 기록했습니다. 이처럼 서로 다른 역할을 맡은 에이전트들이 협업할 때 멀티 에이전트 시스템은 단일 에이전트보다 더 복잡하고 어려운 과제를 처리할 수 있으며, 유연성, 견고성, 확장성 측면에서 강점을 가집니다.
이미지 14. Agent0에서의 Curriculum Agent와 Executor Agent간의 관계. 출처: UNC-Chapel Hill[24]
3. 그렇다면 제논은 어떤 식으로 접근하고 있을까?
최신 기술을 빠르게 도입하여 고객의 문제를 해결해 온 제논은 피지컬 AI를 위한 두 축인 환경과와 에이전트에 대한 각 두 가지 방법 모두에 대해 열린 시각으로 팔로우업(Follow up)하고 있습니다. 2025년 11월을 기준으로 현재 제논의 피지컬 AI에 대한 시각을 공유드립니다.
먼저, 환경의 경우는 2025년 11월 3일에 공개된 코카콜라 광고[25]의 사례와 같이 확산(Diffusion) 모델에 기반한 WFM은 장면마다 차량의 바퀴 수가 변경되는 등 동역학이 중시되는 피지컬 AI에 바로 적용할 수 있을 정도로 고도화되지 않았습니다. 특히 스마트 공장을 포함해 이미 디지털 트윈 기반 환경이 구축·검증된 사례가 많은 상황에서, 제논은 아래와 같은 방식을 통해 WFM에 대한 가장 빠른 팔로우업과 기존 디지털 트윈 기반의 시뮬레이션 방식을 모두 활용하고자 합니다.
코스모스와 제네시스로 대표되는 기본적인 WFM은 다음 상황을 제공하거나, 자체 물리 시뮬레이션을 활용할 수 있도록 제공하고 있습니다. 반면, 좀 더 최신의 WFM인 PhysX-Anything, Marble과 같은 모델들은 미래의 상황을 예측하는 것뿐 아니라 URDF(Unified Robot Description Format),, Mesh, 가우시안 스플래팅(Gaussian Splatting) 등을 추가로 제공하고 있습니다. 저희 제논은 이를 활용하여 시뮬레이션 환경을 빠르게 구축하는 방법을 고민하고 있습니다. 특히, NVIDIA Isaac Sim은 OpenUSD(Open Universal Scene Description)를 기반으로 CAD(Computer-Aided Design), URDF, MJCF(MuJoCo Model Format) 등 다양한 3D 디자인 형식을 지원하여, WFM 뿐 아니라 기존 디지털 트윈 환경으로의 빠른 확장도 가능할 것으로 기대하고 있습니다.
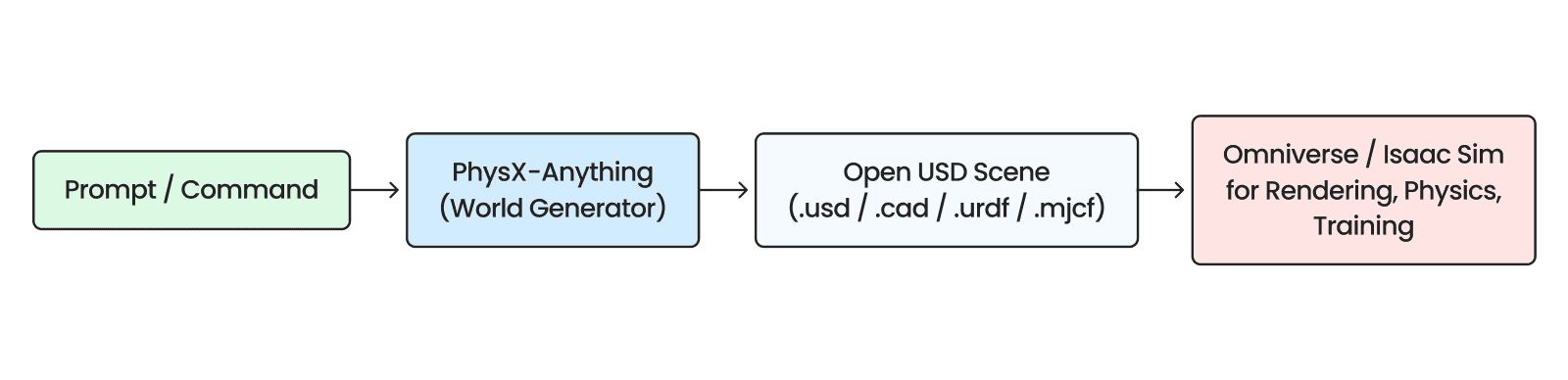
이미지 15. WFM을 활용한 시뮬레이션 환경 구성 방법. 출처: 제논
에이전트의 경우는 환경 보다 더 열린 시각으로 접근하고 있습니다. 앞에서 소개해 드린 내용과 같이 비전 트랜스포머(Vision Transformer, ViT)기반의 엔드 투 엔드 모델이 최근 빠르게 연구되고 있으며, 액셔너블 AI 에서는 멀티 에이전트 시스템가 단일 모델 대비 더 복잡한 기능을 수행할 수 있음을 보이는 연구가 많이 발표된 바 있습니다. 저희 제논은 이 두 가지 방식에 대해 비즈니스 목적에 맞게 접근할 계획입니다. 복잡성이 낮은 테스크에는 가장 최적의 엔드 투 엔드모델을 적용하고, 다중/다종 로봇이 적용되는 복잡한 환경에 대해서는 제논의 AIOps 솔루션인 GenOS를 활용해 중앙 관제와 로봇 간의 협업을 수행할 수 있는 에이전트 AI 워크플로우를 적용하는 방식으로도 접근을 하고 있습니다. 아래 그림은 전통적인 인지/판단/제어 방식에 따른 전문가 에이전트를 도입하여 GenOS를 통해 관제하는 형태의 시스템을 나타냅니다.
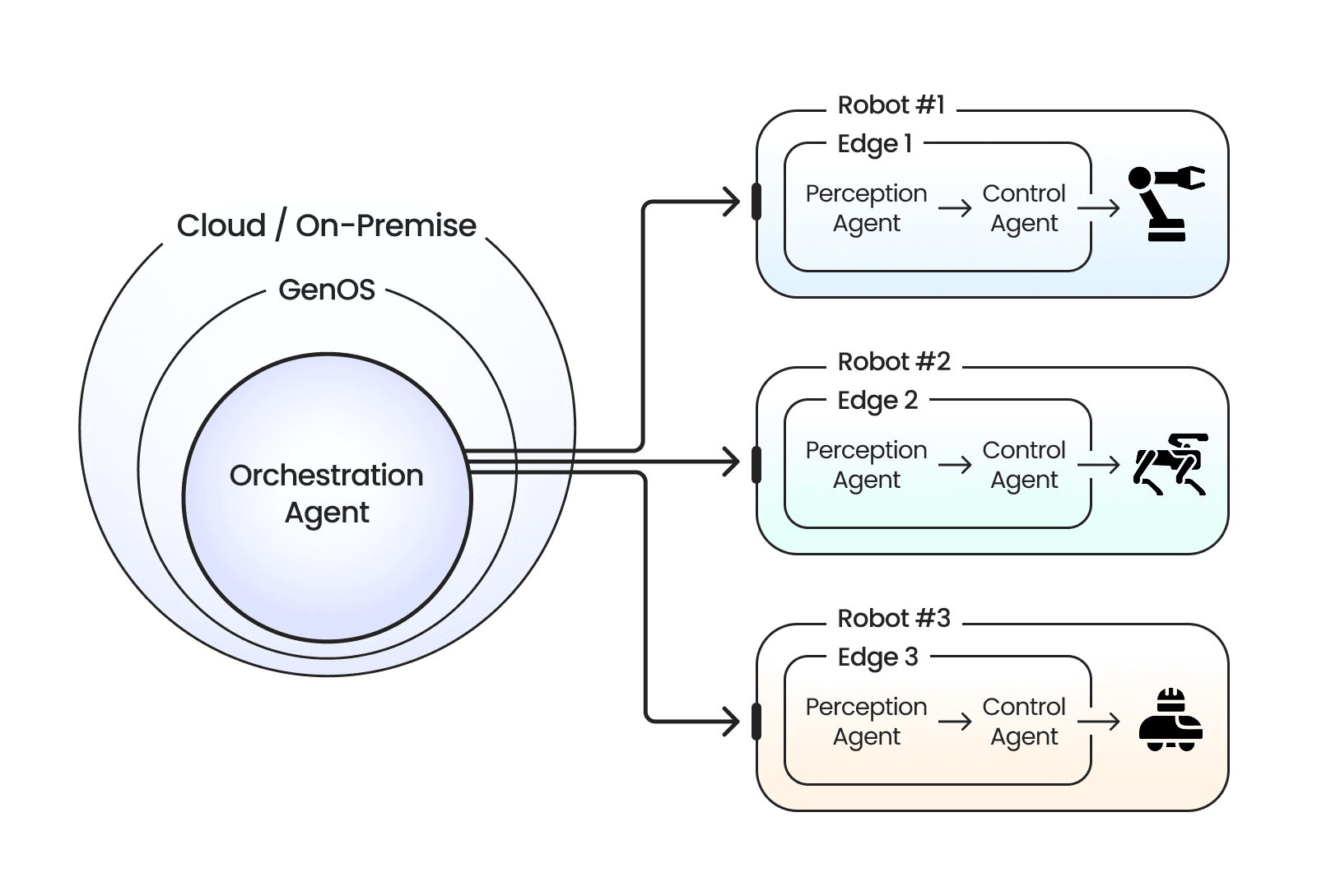
이미지 16. 다중/다종 로봇 환경에서의 멀티 에이전트 시스템 구성 방법. 출처: 제논
본 포스팅에서는 세밀하게 다 다루진 못하였지만 이후 피지컬 AI 시리즈를 포스팅하면서 저희 제논이 갖고 있는 노하우와 연구 사례 등을 다루며 더 깊이 있는 내용을 다룰 테니 이후 포스팅들도 관심 있게 지켜봐 주시길 바랍니다.
이상으로 피지컬 AI에 접근하기 위해 필요한 내용들에 대해 다뤄보았습니다. 피지컬 AI를 구성하는 두 축인 환경과 에이전트에 대한 개념과 최신 연구 내용들을 소개하였으며, 특히 에이전트에 대해서는 엔드 투 엔드 모델과 멀티 에이전트 시스템을 활용한 접근 방식에 대해 소개해드렸습니다.
저희 제논의 피지컬 AI에 대한 2026년 로드맵은 2025년 12월 16일 AIXperience Day에서 자세히 공개될 예정입니다.
제논의 네 번째 AIXperience Day에도 많은 관심 부탁드리며, 앞으로의 제논의 피지컬 AI에 대한 행보도 관심 있게 봐주세요.
최신 기술을 빠르게 도입하여 고객의 문제를 해결해 온 제논은 피지컬 AI를 위한 두 축인 환경과와 에이전트에 대한 각 두 가지 방법 모두에 대해 열린 시각으로 팔로우업(Follow up)하고 있습니다. 2025년 11월을 기준으로 현재 제논의 피지컬 AI에 대한 시각을 공유드립니다.
먼저, 환경의 경우는 2025년 11월 3일에 공개된 코카콜라 광고[25]의 사례와 같이 확산(Diffusion) 모델에 기반한 WFM은 장면마다 차량의 바퀴 수가 변경되는 등 동역학이 중시되는 피지컬 AI에 바로 적용할 수 있을 정도로 고도화되지 않았습니다. 특히 스마트 공장을 포함해 이미 디지털 트윈 기반 환경이 구축·검증된 사례가 많은 상황에서, 제논은 아래와 같은 방식을 통해 WFM에 대한 가장 빠른 팔로우업과 기존 디지털 트윈 기반의 시뮬레이션 방식을 모두 활용하고자 합니다.
코스모스와 제네시스로 대표되는 기본적인 WFM은 다음 상황을 제공하거나, 자체 물리 시뮬레이션을 활용할 수 있도록 제공하고 있습니다. 반면, 좀 더 최신의 WFM인 PhysX-Anything, Marble과 같은 모델들은 미래의 상황을 예측하는 것뿐 아니라 URDF(Unified Robot Description Format),, Mesh, 가우시안 스플래팅(Gaussian Splatting) 등을 추가로 제공하고 있습니다. 저희 제논은 이를 활용하여 시뮬레이션 환경을 빠르게 구축하는 방법을 고민하고 있습니다. 특히, NVIDIA Isaac Sim은 OpenUSD(Open Universal Scene Description)를 기반으로 CAD(Computer-Aided Design), URDF, MJCF(MuJoCo Model Format) 등 다양한 3D 디자인 형식을 지원하여, WFM 뿐 아니라 기존 디지털 트윈 환경으로의 빠른 확장도 가능할 것으로 기대하고 있습니다.
이미지 15. WFM을 활용한 시뮬레이션 환경 구성 방법. 출처: 제논
에이전트의 경우는 환경 보다 더 열린 시각으로 접근하고 있습니다. 앞에서 소개해 드린 내용과 같이 비전 트랜스포머(Vision Transformer, ViT)기반의 엔드 투 엔드 모델이 최근 빠르게 연구되고 있으며, 액셔너블 AI 에서는 멀티 에이전트 시스템가 단일 모델 대비 더 복잡한 기능을 수행할 수 있음을 보이는 연구가 많이 발표된 바 있습니다. 저희 제논은 이 두 가지 방식에 대해 비즈니스 목적에 맞게 접근할 계획입니다. 복잡성이 낮은 테스크에는 가장 최적의 엔드 투 엔드모델을 적용하고, 다중/다종 로봇이 적용되는 복잡한 환경에 대해서는 제논의 AIOps 솔루션인 GenOS를 활용해 중앙 관제와 로봇 간의 협업을 수행할 수 있는 에이전트 AI 워크플로우를 적용하는 방식으로도 접근을 하고 있습니다. 아래 그림은 전통적인 인지/판단/제어 방식에 따른 전문가 에이전트를 도입하여 GenOS를 통해 관제하는 형태의 시스템을 나타냅니다.
이미지 16. 다중/다종 로봇 환경에서의 멀티 에이전트 시스템 구성 방법. 출처: 제논
본 포스팅에서는 세밀하게 다 다루진 못하였지만 이후 피지컬 AI 시리즈를 포스팅하면서 저희 제논이 갖고 있는 노하우와 연구 사례 등을 다루며 더 깊이 있는 내용을 다룰 테니 이후 포스팅들도 관심 있게 지켜봐 주시길 바랍니다.
이상으로 피지컬 AI에 접근하기 위해 필요한 내용들에 대해 다뤄보았습니다. 피지컬 AI를 구성하는 두 축인 환경과 에이전트에 대한 개념과 최신 연구 내용들을 소개하였으며, 특히 에이전트에 대해서는 엔드 투 엔드 모델과 멀티 에이전트 시스템을 활용한 접근 방식에 대해 소개해드렸습니다.
저희 제논의 피지컬 AI에 대한 2026년 로드맵은 2025년 12월 16일 AIXperience Day에서 자세히 공개될 예정입니다.
제논의 네 번째 AIXperience Day에도 많은 관심 부탁드리며, 앞으로의 제논의 피지컬 AI에 대한 행보도 관심 있게 봐주세요.
저자 및 출처
저자
제논 황나영 (Nayoung Hwang | LinkedIn)
제논 권민지 (Minji Kwon| LinkedIn)
제논 김현근 (Hyun-geun Kim | LinkedIn)
출처
[1] 송경. 2025. "인간이 떠난 자리, AI 대타 투입···현대차, '다크 팩토리' 시대 선언". 뉴스그램. https://www.hyundaenews.com/105784
[2] 이민희. 2025. "불 꺼져도 척척척…로봇이 현대차 만든다". 세계일보. https://www.dongbangilbo.co.kr/news/articleView.html?idxno=68548
[3] 신영빈. 2025. "BMW 3만 대 생산한 로봇 은퇴…‘피규어02’가 남긴 기록". 지디넷코리아. https://v.daum.net/v/20251123143549680
[4] NVIDIA. 2025. "Cosmos World Foundation Model Platform for Physical AI". https://arxiv.org/abs/2501.03575
[5] Genesis. "Genesis: A Generative and Universal Physics Engine for Robotics and Beyond". https://github.com/Genesis-Embodied-AI/Genesis
[6] Z Cao et al. 2025. "PhysX-An[7] World Labs. 2025. "Marble: A Multimodal World Model". https://www.worldlabs.ai/blog/marble-world-model
[8] NVIDIA. 2025. "Isaac Sim". GitHub. https://github.com/isaac-sim/IsaacSim
[9] Y Liu et al. 2025. "Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI". arXiv. https://arxiv.org/abs/2407.06886
[10] Gazebo. "rendering". Gazebo Documentation. https://gazebosim.org/libs/rendering/
[11] Arthur Juliani. 2017. "유니티 머신러닝 에이전트 소개". Unity Technologies. https://unity.com/kr/blog/engine-platform/introducing-unity-machine-learning-agents
[12] S Shah et al. 2017. "AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles". https://arxiv.org/abs/1705.05065
[13] Fouad Bousetouane. 2025. "Physical AI Agents: Integrating Cognitive Intelligence with Real-World Action". https://arxiv.org/abs/2501.08944
[14] NVIDIA. 2025. "GR00T N1: An Open Foundation Model for Generalist Humanoid Robots". https://arxiv.org/abs/2503.14734
[15] MJ Kim et al. 2024. "OpenVLA: An Open-Source Vision-Language-Action Model". https://arxiv.org/abs/2406.09246
[16] J Hwang et al. 2024. "EMMA: End-to-End Multimodal Model for Autonomous Driving". https://arxiv.org/abs/2410.23262v1
[17] K Black et al. 2024. "π0: A Vision-Language-Action Flow Model for General Robot Control". Physical Intelligence. https://arxiv.org/abs/2410.24164
[18] MJ Kim, C Finn, P Liang. 2025. "Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success". https://arxiv.org/abs/2502.19645
[19] V Bhat et al. 2025. "3D CAVLA: Leveraging Depth and 3D Context to Generalize Vision Language Action Models for Unseen Tasks". https://arxiv.org/abs/2505.05800
[20] M Shukor et al. 2025. "SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics". https://arxiv.org/abs/2506.01844
[21] NAVER AI Lab. 2025. "Token Bottleneck: One Token to Remember Dynamics". https://arxiv.org/abs/2507.06543
[22] Justin Fu et al. 2020. “D4RL: Datasets for Deep Data-Driven Reinforcement Learning”. https://arxiv.org/abs/2004.07219
[23] Microsoft Research AI Frontiers. 2024. "Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks". https://arxiv.org/abs/2411.04468
[24] P Xia et al. 2025. "Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning". https://arxiv.org/abs/2511.16043
[25] Coca-Cola. 2025. "Coca-Cola | Holidays Are Coming". YouTube. https://www.youtube.com/watch?v=Yy6fByUmPuE
저자
제논 황나영 (Nayoung Hwang | LinkedIn)
제논 권민지 (Minji Kwon| LinkedIn)
제논 김현근 (Hyun-geun Kim | LinkedIn)
출처
[1] 송경. 2025. "인간이 떠난 자리, AI 대타 투입···현대차, '다크 팩토리' 시대 선언". 뉴스그램. https://www.hyundaenews.com/105784
[2] 이민희. 2025. "불 꺼져도 척척척…로봇이 현대차 만든다". 세계일보. https://www.dongbangilbo.co.kr/news/articleView.html?idxno=68548
[3] 신영빈. 2025. "BMW 3만 대 생산한 로봇 은퇴…‘피규어02’가 남긴 기록". 지디넷코리아. https://v.daum.net/v/20251123143549680
[4] NVIDIA. 2025. "Cosmos World Foundation Model Platform for Physical AI". https://arxiv.org/abs/2501.03575
[5] Genesis. "Genesis: A Generative and Universal Physics Engine for Robotics and Beyond". https://github.com/Genesis-Embodied-AI/Genesis
[6] Z Cao et al. 2025. "PhysX-An[7] World Labs. 2025. "Marble: A Multimodal World Model". https://www.worldlabs.ai/blog/marble-world-model
[8] NVIDIA. 2025. "Isaac Sim". GitHub. https://github.com/isaac-sim/IsaacSim
[9] Y Liu et al. 2025. "Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI". arXiv. https://arxiv.org/abs/2407.06886
[10] Gazebo. "rendering". Gazebo Documentation. https://gazebosim.org/libs/rendering/
[11] Arthur Juliani. 2017. "유니티 머신러닝 에이전트 소개". Unity Technologies. https://unity.com/kr/blog/engine-platform/introducing-unity-machine-learning-agents
[12] S Shah et al. 2017. "AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles". https://arxiv.org/abs/1705.05065
[13] Fouad Bousetouane. 2025. "Physical AI Agents: Integrating Cognitive Intelligence with Real-World Action". https://arxiv.org/abs/2501.08944
[14] NVIDIA. 2025. "GR00T N1: An Open Foundation Model for Generalist Humanoid Robots". https://arxiv.org/abs/2503.14734
[15] MJ Kim et al. 2024. "OpenVLA: An Open-Source Vision-Language-Action Model". https://arxiv.org/abs/2406.09246
[16] J Hwang et al. 2024. "EMMA: End-to-End Multimodal Model for Autonomous Driving". https://arxiv.org/abs/2410.23262v1
[17] K Black et al. 2024. "π0: A Vision-Language-Action Flow Model for General Robot Control". Physical Intelligence. https://arxiv.org/abs/2410.24164
[18] MJ Kim, C Finn, P Liang. 2025. "Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success". https://arxiv.org/abs/2502.19645
[19] V Bhat et al. 2025. "3D CAVLA: Leveraging Depth and 3D Context to Generalize Vision Language Action Models for Unseen Tasks". https://arxiv.org/abs/2505.05800
[20] M Shukor et al. 2025. "SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics". https://arxiv.org/abs/2506.01844
[21] NAVER AI Lab. 2025. "Token Bottleneck: One Token to Remember Dynamics". https://arxiv.org/abs/2507.06543
[22] Justin Fu et al. 2020. “D4RL: Datasets for Deep Data-Driven Reinforcement Learning”. https://arxiv.org/abs/2004.07219
[23] Microsoft Research AI Frontiers. 2024. "Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks". https://arxiv.org/abs/2411.04468
[24] P Xia et al. 2025. "Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning". https://arxiv.org/abs/2511.16043
[25] Coca-Cola. 2025. "Coca-Cola | Holidays Are Coming". YouTube. https://www.youtube.com/watch?v=Yy6fByUmPuE
목차

©2025 GenON
13F, 2621 Nambusunhwan-ro, Gangnam-gu, Seoul, 06267, Republic of Korea
|
|
©2025 GenON
13F, 2621 Nambusunhwan-ro, Gangnam-gu, Seoul, 06267, Republic of Korea
|
|
©2025 GenON
13F, 2621 Nambusunhwan-ro, Gangnam-gu, Seoul, 06267, Republic of Korea
|
|